
基于集合和剪枝原理的关联规则隐藏算法
2019-12-04 11:33王诗兵
阜阳师范大学学报(自然科学版) 2019年4期
龚 晨,王诗兵
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001;2.阜阳师范大学 计算机与信息工程学院,安徽 阜阳 236037)
关联规则隐藏是数据挖掘研究的热点,能有效降低大数据时代信息泄露[1-4]。Agrawal等人[5]提出的隐私保护数据挖掘(privacy-preserving data mining,PPDM),而后引起众多学者的关注[6-9]。Bai等人[10]提出了一种启发式双聚类(heuristic double clustering,HBC)算法,主要通过双聚类来隐藏相似数据结构的敏感规则,以提高隐藏准确性,并且在隐藏每个数据项前获得最小迭代次数以提高运算效率。Cheng等人[11]提出了一种从块的角度考虑边界贪心问题,并实现了数据共享的关联规则隐藏问题,既确保了敏感数据的隐藏,又减少不良的副作用。为更好的隐藏具有关联的敏感规则,Yan等人[12]提出一种基于FP-tree树重构事务数据集的关联规则隐藏算法,利用直接删除支持敏感序列的原始序列来达到隐藏的目的。Afzali等人[13]提出匿名化拟合大数据挖掘的模型,并嵌入并行化技术,以提高大数据的关联隐藏力度。Telikani等人[14]提出降低规则置信度(drop confidence rules,DCR)的混合算法,通过两个启发式算法隐藏敏感规则,以控制过程对数据结果质量的影响,且从最短长度的规则中删除关联规则,从而提高敏感数据的隐藏效率。Motlagh等人[15]提出遗传算法的适应度函数,对其所提出的测量值进行调整,达到隐藏敏感规则的效果,并在一定程度上保护了数据信息。
上述隐藏算法,在遍历数据集时都会造成大量I/O资源浪费。基于此,本文提出一种基于集合和剪枝原理的关联规则隐藏算法。首先利用FP-tree原理对其数据集进行后剪枝;接着挖掘频繁序列(即敏感规则),将敏感规则放入集合内;最后以集合为单位进行敏感规则消除[16]。通过与GSP[17]、SPADE[18]算法对比,本文算法既降低了I/O资源浪费,又保障了规则的准确性及高效隐藏性。
1 基于集合和剪枝原理的隐藏算法
基于集合和剪枝原理的关联规则隐藏算法的流程图如图1。算法首先引入FP-tree对原始数据集DB进行后剪枝操作[19-21];然后挖掘敏感规则;接着将敏感规则放入集合中,并以集合为单位对规则进行隐藏消除;最后,将FP-tree结构树中的非敏感规则构造成新的数据集DB'。

图1 基于集合和剪枝原理的关联规则隐藏算法流程图
1.1 敏感规则挖掘
就原始数据集DB而言,将其汇集到FP-tree结构树上,运用基于集合和剪枝原理的关联规则隐藏算法进行后剪枝挖掘敏感规则。具体过程为:先假设有五个事务,序号分别为 1,2,3,4,5。如表1。

表1 测试事务序列数据集
给定最小支持度为3/10,建立频繁模式树,利用后剪枝原理挖掘敏感规则(即频繁序列)如图2。

图2 敏感规则挖掘过程图
1.2 敏感规则消除
基于集合和剪枝原理的关联规则隐藏算法主要是通过删除候选序列中属性相同的,得到敏感规则PFS以及非敏感规则DFS。目的为了实现在满足阈值与支持度的情况下隐藏敏感规则。就关联规则A→B而言,处在最小支持度Minsup与阈值w之间的support减少到Minsup时,根据序列属性的关联性,至少可以删除|(PFS+DFS)×support-support(A→B)|项,其中DFS为属性相同的。同理分析可得,处在满足最小置信度的confidence减少到最小置信度Mincon时,由算法可得:至少可以删除|PFS/(PFS+DFS)×Mincon-support(A→B)|。即可达到敏感规则隐藏的目的。
敏感规则消除,也就是在尽可能保障频繁序列挖掘准确性的情况下,尽可能多的隐藏频繁序列,这也就是本文算法提出的关键所在。此算法的核心思想是利用FP-tree原理去找寻DFS与PFS。通常利用敏感度找寻待删除的敏感规则序列项,选取最小支持度Minsup的序列规则集作为删除规则;将敏感度相同的序列集放在同一个集合中,然后以集合为单位消除所有敏感规则,最终构建新的非敏感规则DB′。在本文中设敏感规则 SR 中包含的敏感项为 sr1,sr2,....,srm。将所有的关联规则放在集合List中,即List={L1,L2,...,Ln},L1,L2,...,Ln都是集合。因此规则敏感度 Sek在集合List内的总敏感度TSek为

式中:敏感度Sek的计算过程表述为[22]
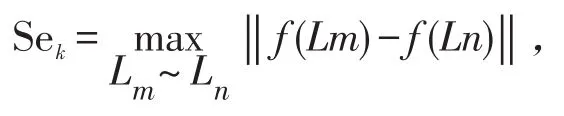
Num(sei)表示规则敏感度的数量。规则敏感度arsm为频繁序列敏感度的总和

同理,集合List的总敏感度TSek可定义成各个集合中所有项的敏感度之和

1.3 构造新数据集
算法对敏感规则进行存储,就如上文所提及的关联规则AB,首先建立FP-tree树进行遍历,后剪枝判断哪些序列为频繁序列。然后利用敏感度寻找敏感规则,并将敏感规则放在同一个List内,消除所有的敏感规则;最后将剩余的非敏感规则构造一个新的数据集DB'。
以图2中的敏感规则CA为例,将支持度sup维持在最小支持度为3/10上,至少需要删除1项;将置信度维持在0.75,至少需要删除规则为2个;所以,关联规则CA的最小删除规则数量为1个。接着,将其放在集合List内,按照同样的原理进行后剪枝得到频繁序列,在利用敏感度找到待删除的敏感规则,最后将其放在相应的集合内,删除所有的敏感规则,得到新的非敏感规则DB'。具体的过程如图3所示。

图3 敏感规则CA索引查找
1.4 算法描述
算法名称:基于集合和剪枝原理的关联规则隐藏算法。
输入:数据集DB,最小支持度Minsup,支持度 support,置信度 confidence,最小置信度 Mincon。
输出:非敏感规则数据集DB'。



2 实验及结果分析
2.1 实验评价指标
关联规则隐藏,就是通过一定的算法将原始数据集DB转换为一个新的数据集DB',使得DB满足以下3个条件:
1)DB'中没有任何敏感规则;
2)DB'中包含DB中的非敏感规则;
3)DB'中不包括任何人为改变的新规则。
关联规则隐藏算法一般采用HF(hiding failure),MS(missing cost),AP(artificial patterns)等 3个指标进行性能评估[1]。

HF表示敏感规则的隐藏失败率,越低说明规则的敏感隐藏效果越好。

MS表示规则丢失率,越低说明DB'质量较高。

AP表示人为规则改变率,越低表明算法产生的人为规则越少。
2.2 实验结果分析
为验证算法的性能,实验中利用真实数据集对本文算法、GSP算法、SPADE算法进行实验测试比较。实验选用了Python语言进行编写,采用的数据集是retail和T10I4D100K两个频繁序列集,网址为http://fimi.ua.ac.be/data/。其中retail的记录为88 162个,T10I4D100K的记录为230 464个。由于数据量较大,因此选取一部分进行实验验证,retail数据集的support和confidence分别设置为7/8和6/7,T10I4D100K数据集的support和confidence分别设置为5/734和1/5。
选取不同数量的敏感规则SR,比较两个数据集上的隐藏敏感规则的失败率HF如图4和5。由于retail数据集的数量小于T10I4D100K数据集,所以上述三种算法在retail数据集上的HF比T10I4D100K数据集的更低,且本文算法在两个数据集的HF均优于其他算法。

图4 retail数据集隐藏敏感规则的失败率

图5 T10I4D100K数据集隐藏敏感规则的失败率
选取不同数量的敏感规则SR,比较两个数据集上的隐藏敏感规则的丢失率MS如图6和7。由于retail数据集的支持度support较大,所以上述三种算法在retail数据集上的MS比T10I4D100K数据集的更低;由于本文算法在找寻最小的敏感数后隐藏敏感规则,因此在两个数据集上的MS均优于其他算法。
选取不同数量的敏感规则SR,比较两个数据集上的隐藏敏感规则的人为规则改变率AP如图8和9。由于三种算法都是通过support和confidence挖掘敏感规则,从而达到敏感规则隐藏的目的,因此,这样三种算法均不会产生太大的AP;隐藏的敏感规则越多,产生的AP会越大;本文算法产生的AP比较少,因此优于其他算法。
选取不同数量的敏感规则SR,比较两个数据集的运行时间如图10和11。由于本文算法减少了输入输出流的资源浪费,因此运行时间明显低于GSP、SPADE,降低了20%~50%的时间。
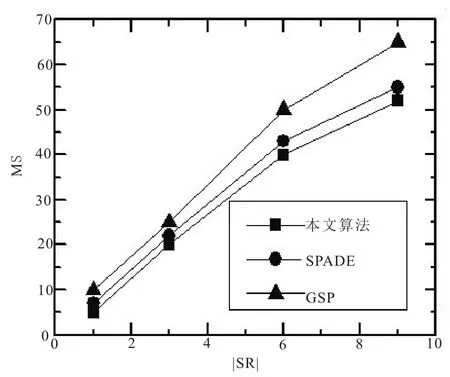
图6 retail数据集隐藏敏感规则的丢失率
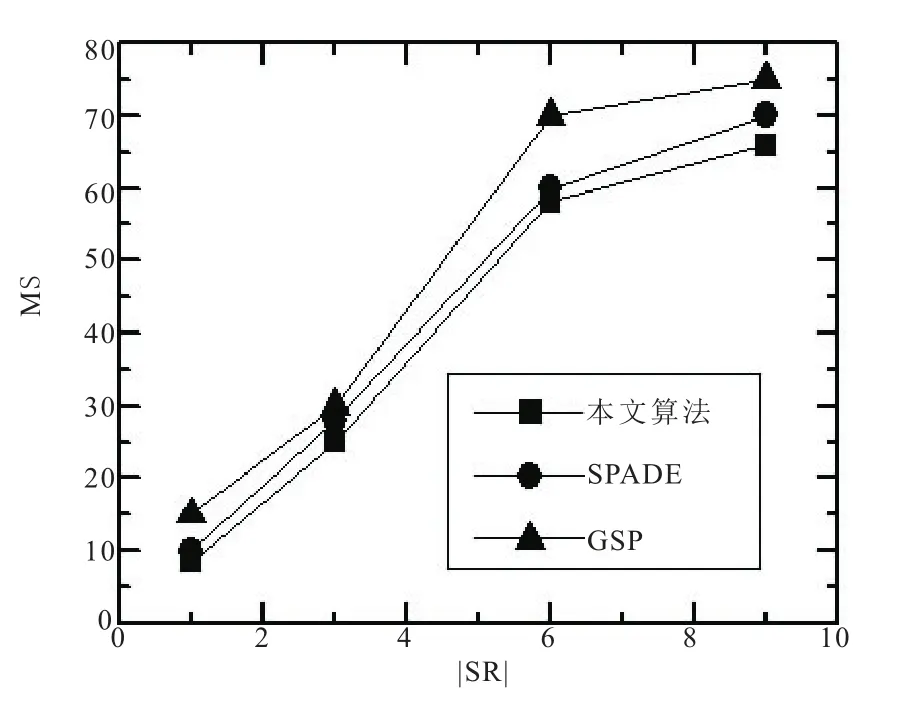
图7 T10I4D100K数据集隐藏敏感规则的丢失率

图8 retail隐藏敏感规则的人为规则改变率

图9 T10I4D100K隐藏敏感规则的人为规则改变率
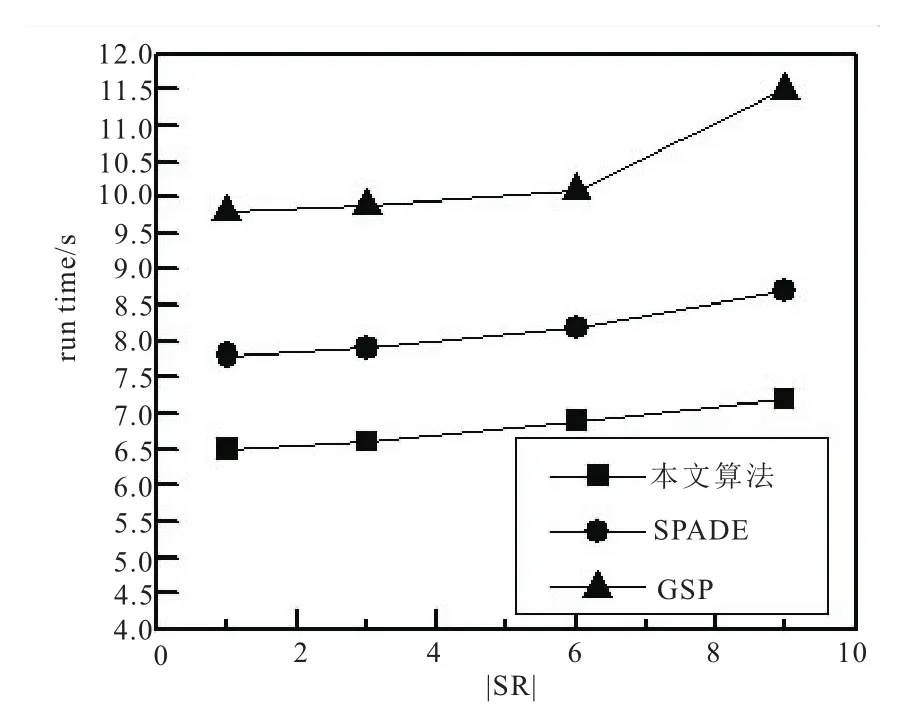
图10 retail数据集隐藏敏感规则的运行时间

图11 T10I4D100K数据集隐藏敏感规则的运行时间
3 小结
为解决现有关联隐藏算法存在的不足,主要是直接遍历数据集时造成大量I/O资源浪费,降低了数据集的质量,本文提出将集合与剪枝原理相结合的关联规则隐藏算法,首先建立FP-tree结构树,利用后剪枝原理处理数据集,接着挖掘敏感规则,并放入集合内,最后以集合为单位进行关联规则隐藏。此算法较明显的降低了挖掘敏感规则的时间,同时也提高了关联规则的隐藏性能,保证了数据集的高质量性。但本文只验证了一部分大型数据集的性能指标,在下一阶段的研究中,将完善大型数据集的验证。
猜你喜欢
保健医苑(2022年5期)2022-06-10
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
成都信息工程大学学报(2021年6期)2021-02-12
数学年刊A辑(中文版)(2020年2期)2020-07-25
计算机应用(2020年5期)2020-06-07
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
计算机应用(2018年5期)2018-07-25
天津诗人(2017年2期)2017-03-16
