
面向大图的Top-Rank-K 频繁模式挖掘算法
2024-03-24 03:10邹杰军石俊豪谢文波沈玲珍
南京大学学报(自然科学版) 2024年1期
邹杰军,王 欣,石俊豪,兰 卓,方 宇,张 翀,谢文波,沈玲珍
(西南石油大学计算机科学学院,成都,610500)
频繁模式挖掘(Frequent Pattern Mining,FPM)是知识发现和图挖掘的重要问题之一,其目的是从给定数据集中挖掘支持度不小于用户指定阈值的所有模式.FPM 主要有两种不同的设定:基于图集的FPM 和基于单个大图的FPM.近年来,后者广泛应用于社交网络[1]、计算机化学[2]、生物信息学[3]、网络安全[4]等领域,备受关注.现有的方法大多遵循组合模式的枚举范式,然而在某些实际应用场景,如社交网络中,枚举所有频繁模式的代价是昂贵且非必要的[5].
在频繁模式挖掘任务中,频繁模式被定义为支持度不小于给定阈值的模式,因此支持度阈值是频繁模式挖掘任务中的一个重要输入参数.通常模式的支持度度量应满足反单调性,即父模式的支持度不小于子模式的支持度.基于该特性,挖掘算法能有效地进行搜索空间的剪枝,然而,在算法运行之初,确定合适的支持度阈值难度较大.
例1图1a 展示了一个社交网络图G,其中每个顶点表示一个具有特定ID 和职称的用户(如项目经理(PM)、数据库管理员(DBA)、程序员(PRG)、业务分析师(BA)和软件测试人员(ST)).图中的边表示人与人之间的好友关系.特别地,顶点v1~v5被分组在一起,表示他们具有相同的职称BA;类似地,顶点v16~v30表示他们具有的相同职称DBA.两个不同分组间的联系表明,组内用户与邻接组内的任意用户都存在好友关系.在图G上执行不同支持度阈值下的FPM任务时,频繁模式的数量存在显著差别.例如,当θ=5 时,可挖掘出Q1到Q100共计100 个模式(如图1b 所示).值得注意的是,如果Q1~Q100全部被返回,那么用户将不得不面对大量的频繁模式,这些频繁模式不仅包含“冗余”信息,而且计算代价昂贵.与此同时,当θ=15 时,仅仅挖掘出七个模式(Q1,…,Q7).因此,根据实际应用需求,明确合适的支持度阈值往往较为困难.
上述例子表明:(1)支持度阈值设置过大会导致返回的模式数量过少,且模式中单边模式的占比过大,实际应用价值偏低;(2)一个过小的支持度阈值会返回过多的模式,使用户难以找到满意的模式,还会增加算法的搜索空间和计算开销,严重的甚至可能导致程序因内存溢出而崩溃.
此外,现有的Top-Rank-K 频繁模式挖掘算法(如NTK[6]和iNTK[7])主要应用于事务型数据库的频繁项集挖掘.随着图数据对描述关系的优势日渐显现,频繁模式挖掘的研究逐渐扩展到包含图结构数据的领域,已提出多种针对Top-K 频繁模式 挖掘的算法(如PBSM[8],Resling[9]和Dminer[10]),但它们都需要预先设定一个初始支持度阈值,并且仅用模式自身的支持度来衡量模式的价值,导致挖掘结果偏向小而频繁的模式.
以上观察激发了本文对单一大图上的Top-Rank-K 频繁模式挖掘问题的探究,即在无初始支持度阈值的情况下高效地挖掘排名前k的频繁模式.为此,本文需要解决以下两个关键问题.
(1)设计一个兴趣度指标来对模式进行排名,该指标在理想状态下能同时考虑模式的支持度和模式的大小.
(2)设计一种有效的算法,在没有初始支持度阈值输入时也能高效地进行频繁模式挖掘.
本文的具体贡献如下.
(1)提出一种基于模式大小和模式支持度的模式兴趣度度量指标.
(2)提出一种无须设置初始支持度阈值的Top-Rank-K 模式挖掘算法ItrMiner,只须输入图G和一个整数k就能返回兴趣度排名在前k名的模式.对无初始支持度阈值可能导致的大量低兴趣度模式问题,ItrMiner 采用兴趣度优先的树模式识别策略和一种新颖的模式扩展约束条件,有效减少了低兴趣度候选模式的生成,显著提升了挖掘效率.
(3)在真实图和人工合成图数据集上进行了广泛的实验研究,验证了ItrMiner 的性能.首先,ItrMiner 模式的扩展约束有效性较高,和无扩展约束优化的ItrMinernopt相比,效率提升最高可达9.5 倍;其次,与Grami 算法进行了对比,验证了ItrMiner 的有效性和可行性,为传统频繁模式挖掘提供了一种有价值的替代方案;另外,ItrMiner的执行效率和可扩展性表现良好,尤其在稠密的数据集上,其时间开销仅为基线算法Top-K Graph Miner(TKG)的13.2%.
1 相关工作
Top-Rank-K 频繁模式挖掘最早由Deng and Fang[11]提出,以模式的支持度作为排名的参考,用于在事务型数据库中寻找排名前k的频繁项集.还有大量集中在频繁项集上的Top-Rank-K模式挖掘研究,主要分两个方向扩展:第一种是算法性能优化,如NTK[6],iNTK[7]和TK-FIN 算法[12]等;第二种是横向功能上的扩展,例如从不确定数据中挖掘Top-Rank-K 模式的UFAE 算法[13]和用于挖掘带权重的频繁项集等的TFWIN+算法[14].
图数据在描述数据关系方面的卓越表现日益凸显,频繁模式挖掘的研究方向逐渐从传统的事务型数据库扩展到包含图结构数据的领域,单一大图数据的频繁模式挖掘问题受到了众多学者的关注.其中,Sigram[15]和Grami[16]是两种代表性算法.Sigram 采用支持度大于指定阈值的顶点来扩展模式并生成候选模式,通过搜索候选模式的匹配来计算其支持度,然而,采用存储模式匹配来计算支持度的方式会消耗大量内存.为了解决这一问题,Elseidy et al[16]提出Grami 算法,将子图同构查找问题转换为约束满足问题CSP(Constraint Satisfaction Problem),通过MNI(Minimum Image)支持度规则,找到足够的证据来证明该模式是频繁的部分匹配.
随着图结构数据规模的增大,为了提高在单图上进行频繁模式挖掘的效率,Arabesque[17],Fractal[18]和ScaleMine[19]等分布式挖掘算法被提出.其中,Arabesque 采 用BFS(Breadth First Search)策略来识别频繁模式,导致每个工作站点需要生成并存储大量的中间状态,内存开销较大.为了解决该问题,Fractal 采用DFS(Depth First Search)以及模式重复生成策略,有效降低了内存消耗,并且使用局部感知的任务窃取策略来实现动态负载均衡.另一个分布式系统Scale-Mine 将模式挖掘分成近似挖掘和精确挖掘两个阶段工作,通过近似挖掘的结果来指导精确挖掘阶段的负载分配,实现更好的负载平衡,提升了算法的执行效率.和上述分布式算法相比,G-Miner[20]采用一种细粒度的图划分方法来保证分割子图的局部性,并通过任务窃取策略来实现负载均衡.该方法不再需要每个工作站点都加载完整的输入图,可以有效地处理数据规模超过单机内存的超大单图.此外,与G-Miner 采用的图划分方法不同,李玲等[21]提出一种基于垂直分解框架的分布式框架,并设计了Desu-FSM 算法,旨在挖掘大规模图中的封闭子图.
实际应用中用户通常只关注最感兴趣的前k个模式,因此,Top-K 模式挖掘的重要性逐渐显现.例如,为了降低枚举成本,Chen et al[8]引入基于等价顶点的图压缩技术对数据进行预处理来挖掘前k个最频繁的子图.为了满足用户对不同兴趣度指标的需求,Natarajan and Ranu[9]开发了一个名为Resling 的通用框架,通过基于随机游走的算法对模式进行多样性排名来挖掘前k个最具代表性的频繁模式.与Resling 类似,Wang et al[10]重新定义模式的多样性,设计了一种多样性挖掘前k个频繁模式的Dminer 算法.为了进一步提高算法的执行效率,AprTopK[22]采用逐层扩展策略,近似挖掘满足支持度阈值的前k个最大频繁模式.
对于频繁模式挖掘,还有部分工作专注于避免支持度阈值设置的困扰,提出了无须设置初始支持度阈值的算法.其中,TGP[23]采用名为Lexicographical Pattern Net 的结构来存储所有子图的DFS 代码,并利用该结构来挖掘前k个最频繁的封闭子图,但由于TGP 需要显示生成所有模式,执行效率不高.为了解决这一问题,Saha and Al Hasan[24]提出一种基于MCMC(Markov Chain Monte Carlo)抽样的方法FS3来挖掘概率意义上的前k个最频繁的子图.FS3通过采样再挖掘的方式,有效地提升了算法的运行效率,但无法准确发现所有的模式.因此,Fournier-Viger et al[25]提出一种采用动态规划策略实现快速提升支持度阈值的精确挖掘算法TKG.此外,FastPat[26]引入元索引的概念,通过预先指定核心模式,在知识图谱中挖掘出前k个支持度最大的频繁模式.
虽然现有方法可以识别满足支持度阈值的全部或前k个频繁模式以及通过一些约束条件在不设定支持度阈值的情况下识别前k个最频繁的模式,但它们都没能有效解决在不设置支持度阈值的情况下综合考虑模式的大小和支持度以挖掘用户更满意的模式的问题.本文提出基于图数据的新型频繁模式挖掘方法,实现了在无支持度阈值的情况下准确地挖掘兴趣度排名在前k的频繁模式.该方法引入一项结合模式大小和支持度的“兴趣度”函数来评估模式的价值,改进了仅使用支持度度量模式的传统方法.此外,为了提高挖掘效率,还设计了一项有效的剪枝过滤技术.
2 基本概念
本文研究的数据集包含带标签的图,每个点都有一个标签来描述其属性.首先回顾图、模式和模式匹配的概念,再对频繁模式挖掘进行形式化描述.
2.1 图、模式与模式匹配
定义1 图和子图给定三元组标签图G=(V,E,L),其中,V是顶点集合;E⊆V×V是边集合;V中每个节点v携带L(v),表示其标签或内容.
图G的子图Gs表示为Gs=(Vs,Es,Ls)的 三元组,其中,Vs⊆V,Es⊆E,针对每个节点v∈Vs,都有Ls(v)=L(v),称图Gs为图G的一个子图.
定义2 模式和子模式给定一个模式Q=(Vp,Ep,fv),其中,Vp和Ep分别是节点和边的集合;针对每一个u∈Vp,fv(u)被定义为′A=a′形式的原子公式的连结,A表示节点u的一个属性,a是属性A对应的值.通过一次模式扩展,可以得到模式Q′=(Vp′,Ep′,f v′),其中,Q′⊇Q.Q′比模式Q多一条边和一个顶点(也可能只多一条边).同时,模式Q称为父模式,模式Q′称为子模式.
定义3 模式匹配给定图G=(V,E,L)和模式Q=(Vp,Ep,fv),如果G中节点v满足Q中节点u的查询条件,即对于每一个fv(u)中的原子公式A=a,在L(v)中都有对应的属性A,使得v.A=a,则称v是u的匹配,并用v~u表示两者间的匹配关系.
图G中模式Q的匹配是一个从Q到G的同构映射f,使得:
(1)对于每个节点u∈Vp,fv(u)~L(f(u));
(2)对于每个模式边(u,u′) ∈Ep当且仅当(f(u),f(u′))∈E.
这样,当模式Q与G的子图Gs=(Vs,Es,Ls)存在同构映射关系f时,Gs为Q在G中的一个匹配.
模式Q在G中的匹配通常不止一个,本文使用M(Q,G)表示模式Q在图G中的所有匹配.
例2图2a的图Ga中存在一个具有点集{BA,PM,DBA,ST}的模式Q,能找到八个匹配,分别为Gs-1到Gs-(8图2c).每个匹配的顶点与模式Q的点相互对应.例如Gs-1中的点集{v2,v5,v9,v12}分别对应Q的点集{BA,PM,DBA,ST}.

图2 样本图、模式、模式定义域及其模式匹配Fig2 .A sample of graph,patterns,domains and their matches
定义4 前向扩展和后向扩展给定模式Q,可以通过从其节点u对Q进行深度优先搜索来构建其DFS 树Tq,称Tq中的边为前向边,称Q中的其余边为后向边.因此,前向扩展通过引入一条从Q中的现有顶点到新引入的顶点的新边来扩大Q,扩展出来的模式形如树状结构,被称为树模式.后向扩展从Q的两个现有顶点引入新边,扩展出来的模式,其结构中包含回边,不再是树状结构,被称为非树模式.
例3如图2b 所示,θ=15 时存在三个模式Q1,Q2和Q7.Q2可以通过前向扩展从具有边集{(DBA,PRG)}的模式Q1生成,该过程增加了一个顶点ST 和一条边(PRG,ST);Q2还可以通 过后向扩展,在不增加节点的情况下,增加一条新边(DAB,ST),生成新的模式Q7.
定义5 模式大小给定模式Q=(Vp,Ep,fv),其模式大小定义为 |Q|=|Ep|,其中,|Ep|为模式的边数.
不少工作中,模式的大小被定义为点集与边集大小的和,而本文对此进行调整,主要因为模式无论通过前向还是后向扩展,其边数都会增加1,而点数在后向扩展时保持不变,故采用边集的数量来描述模式大小的增长会更平滑.因此,本文将模式大小 |Q|定义为 |Q|=|Ep|.
2.2 频繁模式挖掘
定义6 支持度给定模式Q和图G,支持度表示模式Q在图G中对应匹配出现的频率,记为Sup(Q,G).
基于图像的最小支持度[27]是一个广泛使用的度量标准,它保证了模式扩展的反单调性.本文用其来计算模式的支持度,其定义如下所示:
其中,P(u)表示模式中顶点u在图G上的匹配去重后的节点集合.
例4如图2b 所示,模式Q在图G上的匹配去重之后得到的结果为:
定义7 反单调性给定图G的任意两个模式Q,Q′,如 果Q′是Q的子模式,则一定存在Sup(Q,G)≥Sup(Q′,G),即子模式频繁,父模式也一定频繁,称模式具有反单调性.
定义8 域给定图G和具有节点集Vp的模式Q,Q的域(Domain)用D(Q,G)表示.模式Q的域将Q在G中 的所有 匹配M(Q,G)重新组 织为一个表,表的列头和列体分别对应模式节点ui(ui∈Vp)和它的映射P(ui).
例5如图2c 所示,模式Q在图Ga中的所有匹配M(Q,Ga)包括Gs-1到Gs-8,共计八个匹配,而Q的域D(Q,Ga)(图2b)是一个比M(Q,Ga)更紧凑的数据结构.
定义9 频繁模式挖掘给定图G和支持度阈值θ,频繁模式挖掘旨在从图G中发现一个频繁模式集合S,S中的任意模式Q的支持度满足Sup(Q,G)≥θ.
表1 给出了本文中重要的符号及其含义.

表1 本文使用的符号Table 1 Summary of notation
3 Top-Rank-K 模式挖掘算法
3.1 问题描述下面给出Top-Rank-K 模式挖掘问题的形式化描述.
输入:单个大图G和一个整数k.
输出:一个从G中发现的频繁模式集合Sk,该集合中的任意模式Q的rank,即R(Q)满足R(Q)≤k.
这里,R(Q)是模式Q的兴趣度排名,具体定义如下所示:
其中,I是一个由所有模式的不同兴趣度组成的集合.模式Q的R(Q)被定义为兴趣度大于等于Itr(Q)的不同兴趣度的数量.特别地,当两个模式的兴趣度相同时,它们的rank 相同.模式Q的兴趣度的定义如下所示:
其中,Sup(Q,G)为模式Q的支持度,是一个由系数α(α>1)和模式大小 |Q|共同决定的衰减系数.
直观上,Top-Rank-K 模式挖掘任务旨在从图G中找到所有rank 不大于k的模式.
在设计模式兴趣度时,从应用出发,考虑两个因素:(1)模式的支持度越大,兴趣度越高;(2)模式的规模越大,兴趣度越高.然而,随着模式规模的增长,支持度必然会单调递减.对此,基于削减小模式支持度收益的思想,本文设计了如式(3)所示的兴趣度度量函数,在考虑模式大小的同时,尽可能降低不具备反单调性的影响,使基于传统支持度剪枝的效果可以有效地保留.
本文中参数α的值预设为2.0.计算可得α=2.0,模 式大小为1 时(单边模式),Itr(Q)≈Sup(Q,G)×0.67;模式大小趋近无穷大时,Itr(Q)≈Sup(Q,G).因此,本文选择α=2.0,在平衡模式大小和支持度两方面具有一定优势,可以弱化小模式支持度过大以及大模式支持度偏低带来的影响,这个选择既符合实际需求,又易于计算.后文的实验部分将更深入地讨论参数α对算法性能的影响.
例6图1b 中的两个模式Q7和Q100在图G中(图1a)的支持度分别为15 和5.通过式(3)计算可得Itr(Q7)=13.35,Itr(Q100)=4.95.由 于Itr(Q7)>Itr(Q100),因此,对于用户,Q7被认为是更有价值和更有趣的模式.
命题1Top-Rank-K 模式挖掘是NP-hard问题.
证明子图同构(Subgraph Isomorphism,SISO)可以检测图G中是否存在子图与Gs同构.该问题被嵌入Top-Rank-K 模式挖掘问题,则Top-Rank-K 模式挖掘问题至少与SISO 问题具有相同的难度,由于SISO 是一个NP-hard 问题[28],因此Top-Rank-K 模式挖掘问题也是NP-hard 问题.
由于算法无须输入支持度阈值,故其无法直接用支持度阈值进行搜索空间的剪枝.另一方面,直接对整个搜索空间进行穷举显然不可取.为了纠正这一点,算法采用兴趣度优先的树模式识别方法并结合严格的模式扩展约束来降低不必要的搜索开销,具体将在下文中详细介绍.
3.2 整体框架如算法1 中的伪代码所示,ItrMiner 以图G和整数k为输入,返回一组rank 不大于k的模式作为输出.挖掘过程中ItrMiner 执行三项主要任务:初始化(第1~4 行)、兴趣度引导的树模式识别(第5~15 行)和非树模式挖掘(第16 和17 行).所有模式都被组织在一个动态维护的有向树T(称为编码树)中,T的增长遵循自上而下的方式,从“种子”模式开始(单边模式).

3.3 初始化算法1 一共初始化了Sc,Sk,L,T,sEdges和minItr六个参数.首先,在第1 行,初始化两个空的优先队列Sc和Sk以及用来存储中间过程生成的候选模式的空集合L;在第2 行,创建一个空的编码树T;在第3 行,初始化图G中的所有单边sEdges,并将最小兴趣度minItr设定为1.Sc存储待扩展的候选模式并以支持度作为比较条件,模式支持度越高,排名越靠前.Sk存放迭代的Top-Rank-K 模式,算法结束时最终返回的结果为Sk中的模式,并以模式的兴趣度为比较条件,兴趣度越低,排名越靠前.值得注意的是,Sk的大小由不同兴趣度的个数决定且最大值为k,当Sk超过k时,移除队首元素(最小值).然后,在第4 行,ItrMiner 进行单边初始化,计算每个单边模式(即“种子”模式)的支持度和兴趣度,按它们各自的大小依次加入Sc和Sk,并添加对应种子模式的节点到编码树T.注意,在这个过程中,若Sk的大小达到k,则用Sk中最小的兴趣度更新minItr.
例7图1a所示的社交网络上图G上,ItrMiner首先识别出八个“种子”模式Q1~Q(8如图3 所示),它们的兴趣度如表2 所示.根据它们各自的兴趣度将其分别插入Sc和Sk(k=4).由于k=4,Q5和Q8的rank 排名分别为5 和6,因此不插入Sk.模式Q2,Q3和Q7的兴趣度最低,为6.70,放置于Sk的队首;模式Q6的兴趣度最高,为13.40,放置于Sk的队尾.Sc中Q6的支持度最高,为20,放置于队首;Q2的支持度最低,为10,放置于队尾.值得注意的是,Q5和Q8的支持度小于Sk当前的最小兴趣度6.70,因此不插入Sc,因为后续无论怎么扩展,它们的模式的兴趣度都不会大于6.70.

表2 种子模式的支持度,兴趣度和rank 排名Table 2 Support,interestingness and ranking of seed patterns

图3 编码树生成和队列更新Fig.3 Coding tree generation and queue update
3.4 兴趣度优先的树模式识别在这一阶段,ItrMiner 以兴趣度为优先级,通过函数FwTree-Gen 扩展当前支持度最高的模式,以尽快提升最小兴趣度minItr并剪掉低兴趣度的模式.具体地,当Sc≠∅时,算法1 第6 行不断地从Sc中弹出顶部元素(当前支持度最大的模式)Q,并执行以下操作:(1)算法1 第7 行和第8 行,验证Q的支持度,如果Sup(Q,G)<minItr,则结束while 循环,因为后续的模式无论怎么扩展,其兴趣度都小于minItr;(2)算法1 第9 行调用函数FwTreeGen 对模式Q进行前向扩展,生成一组候选模式L,在这个过程中,每个新模式的域会基于模式Q的域进行更新;(3)对于L中的每个候选模式Qe,算法1第10~13 行检查Qe是否出现过,如果它是一个新模式并满足Itr(Q)≥minItr,则将Qe添加到Sk和Sc,并通过Sc来更新T.此外,算法1 第14~15 行对Sk的大小进行验证,如果Sk≥k,则更新minItr.
例8如图3 所示,将八个种子模式Q1~Q8存储进编码树,然后ItrMiner 以兴趣度优先的树模式识别方式逐一调用函数FwTreeGen 前向扩展编码树T上的模式来不断地生成候选模式.例如,模式Q6的支持度最高,先从Sc出队,由于扩展约束的限制,Q6不能扩展(详见4.6).接着,Q1出队,通过前向扩展得到模式Q11,然后计算Q11的支持度和兴趣度,将其分别插入Sk(k=4)和Sc.由图可见,经过步骤①,Sk(k=4)的兴趣度集合由 (13.40,10.72,10.05,6.70)更新为(13.40,12.80,1 0.72,10.05),删除了6.70,增添了Q11的兴趣度12.80.对于Sc,Q6和Q1出队,新模式Q11加入队列并按照其支持度大小放置在相应的位置.值得注意的是,Q2,Q3和Q7的支持度(10)小于当前Sk(k=4)的最小兴趣度10.05,因此更新Sc,将它们删除.
3.5 非树模式挖掘非树模式挖掘,即后向扩展,是在当前模式的基础上继续增添新的边.算法2 展示了后向扩展的具体细节.

编码树T构建完成后,ItrMiner 调用函数BackSearch 来挖掘非树模式.具体地,Back-Search 首先初始化一个整型参数h=1,然后迭代地生成非树模式,模式生成过程遵循自顶向下的方式,从位于T顶层的编码树开始.每一轮迭代中,算法2 第4~7 行,BackSearch 在T的h层优先选择支持度最大的模式Qhi,并利用BwTreeGen生成一组候选模式L.这个过程中会优先比较Sup(Qhi,G)与minItr的大小,如果Sup(Qhi,G)<minItr,则终止当层循环.值得注意的是,BwTreeGen 的工作原理类似FwTreeGen,但仅通过后向扩展方式来扩展Qhi.算法2 第9~12 行对L中的每个候选模式Qe进行验证,如果是未被扩展出的模式并且其兴趣度大于等于minItr,则将Qe加入Sk并更新minItr.
例9当树模式识别完成之后,BackSearch调用函数BwTreeGen 后向扩展编码树T上的模式来不断地生成候选模式,从而实现非树模式的挖掘.具体地,由于编码树的顶层节点都是单边模式,不能进行后向扩展,故BackSearch 直接从第二层开始遍历.如图3 所示,Q11,Q41和Q42都是第二层模式,Q11的支持度最高,因此首先扩展Q11,通过函数BwTreeGen 扩展得出环形模式Q11-1,BackSearch 计算其支持度和兴趣度,将其分别插入Sk(k=4)和Sc,再继续扩展Q41和Q42.由于其扩展结果与Q11-1相同,因此当前Sk存放的即为最终结果,BackSearch 将其返回.
3.6 模式扩展约束规则为了解决传统的使用频繁单边进行扩展的方法在Top-Rank-K 模式挖掘中产生大量低兴趣度模式的问题,提出模式扩展约束规则,要求每个模式都有一个扩展约束支持度Q.cst,并在单边e对模式进行扩展时需要满足Q.cst≤sup(Qe,G),即单边对应的模式支持度大于等于被扩展模式的约束支持度.值得注意的是,“种子”模式的扩展约束支持度为其支持度本身,而子模式继承了父模式的扩展约束支持度.
命题2有约束的模式扩展不会错过任何一个模式的生成.
证明给定图G的所有单边模式e1,e2,…,en,其中,sup(e1,G)≥sup(e2,G)≥…≥sup(en,G).给定任意模式Q=(V,E(ei,ej,…,ek),f),i<j<k.由于模式扩展的约束,模式Q无法由单边模式ei,ej扩展而得,但其总能被扩展约束的最小的ek扩展出来.因此,有约束的模式扩展不会错过任何一个模式的生成.
例10如图3 所示,Sc队首元素Q6出队,通过模式扩展约束规则可知Q6.cst=20.由于没有其余单边模式的支持度大于等于20,因此Q6无法进行扩展.紧接着Q1出队,因为Q1.cst<sup(Q6,G),所以Q1通过Q6扩展生成模式Q11.图4 所示为无约束的模式扩展编码树.与有约束的模式扩展相比,在结果相同的情况下,无约束的模式扩展产生了25 个冗余模式.最后经过检验,这些模式均被证实为不频繁(其模式兴趣度小于当前Sk的最小兴趣度).

图4 未带约束的模式扩展编码树Fig.4 Pattern expansion coding tree without constraints
上述例子表明,在结果相同的情况下,采用带有约束的模式扩展策略,搜索空间会更小,算法的执行效率更高.下文将详细探讨这种优化对算法性能的影响.
4 实验
为了全面评估ItrMiner 算法的性能进行了实验研究,并与基线算法进行比较.实验涵盖了真实图数据和合成图数据,考察算法的运行时间、内存消耗和可扩展性.每个实验重复五次,并对结果进行平均处理.
测试环境为一台配备2.5 GHz 48 核CPU 和192 GB RAM 的服务器,操作系统为CentOS Linux release 7.8,实验代码均用java 编写.
4.1 实验数据使用如表3 所示的六个真实数据集.

表3 实验使用的数据集Table 3 Datasets used in experiments
(1)Amazon[29]是产品联合采购网络,包含0.41×106个点和3.35×106条边.当两个商品a和b被客户同时购买的频次达到一定数量时,就会形成边(a,b).
(2)MiCo[16]是由微软合作作者信息构建的网络,包含0.1×106个点和1.08×106条边.每个节点代表作者,每条边代表两位作者之间的合作关系.
(3)YouTube[30]是由来自YouTube 平台的视频及其相关视频构建的网络,包含0.15×106个点和1.05×106条边.每个节点代表一个用户或频道,每条边代表两个节点之间的关系.
(4)Twitter[31]是来自Twitter 平台的社交网络,包含八万多个点和1.76×106条边.每个节点代表一个Twitter 用户,每条边代表两个用户的关注.由于原始图数据没有标签,因此随机地对节点添加标签,标签分布服从高斯分布.
(5)CiteSeer[16]是计算科学领域的引文网络,包含三千个点和四千条边.每个节点代表一篇学术论文,每条边代表两篇论文之间的引用关系.
(6)PDB[32]是来自PDB 的一个蛋白质结构网络,包含两万多个点和八万多条边.每个节点代表一个原子,每条边表示分子之间的化学键.
4.2 实验设置使用4.1 的六种真实图数据集和通过图生成器生成的10 种不同大小规模的人工合成图数据集.
使用Java 实现ItrMiner 和以下算法.
(1)TKG.通过实现TKG 算法[25]并对其加入支持单个大图中的支持度和兴趣度的计算,使其能在单个大图中挖掘Top-Rank-K 频繁模式.
(2)Grami.是一种改良版的Grami 算法[16],在Grami 的基础上引入本文提出的兴趣度计算来挖掘Top-Rank-K 频繁模式.具体地,首先挖掘得到所有的频繁模式,随后计算其兴趣度,经排序后返回前k名的所有模式.值得一提的是:①由于Grami 依赖支持度阈值进行剪枝,因此,算法利用启发式方法来估算支持度阈值;②Grami 在挖掘过程中仅对候选模式进行支持度的判别,即是否达到支持度阈值,没有精确计算对模式的支持度,故本文采用模式支持度下界,即将支持度阈值作为模式的支持度来进行兴趣度值的计算.
(3)ItrMinernopt.是ItrMiner 无模式扩展约束的版本,与ItrMiner 相比,ItrMinernopt除了在模式扩展中没有实现扩展约束以外,其余基本一致.
4.3 实验结果
4.3.1 实验一:k 对算法的影响首先,固定系数α=2.0,在六个真实数据集上,以50 为增量,k从100 增加到300.图5 展示了六个真实数据集上所有算法的执行时间.

图5 在六个数据集上k 对各算法执行时间的的影响Fig.5 The execution time of each algorithm with different k on six datasets
(1)随着k的增加,所有算法的执行时间均变长,因为需要验证的候选模式以及匹配增加了.需要注意的是,CiteSeer 的执行时间基本不变,这是因为预设的k已经大于需要验证的所有候选模式的兴趣度的数量.
(2)与TKG 和ItrMinernopt相比,ItrMiner 的效率更高,在六个真实数据集上,ItrMiner 平均花费的时间分别为TKG 的51.9%,39.2%,43.9%,18.7%,76.5%和94.4%.同时,ItrMiner 的模式扩展约束对提升执行效率有显著作用,在六个真实数据集上,加入模式扩展约束后,ItrMiner 平均花费的时间是ItrMinernopt的45.4%,32.3%,40.4%,14.1%,74.7%和78.0%.此外,ItrMiner在稠密的数据集上的表现尤为出色.以Twitter数据集为例,当k=250 时,ItrMiner 和ItrMinernopt相比,最高效率可提升9.5 倍.同时,和TKG 相比,ItrMiner 仅需花费其13.2%的时间.
图6 展示了各算法在六个真实数据集上的内存消耗.由图可见,随着k的增大,ItrMiner,ItrMinernopt和TKG 的内存消耗也相应增加,这是因为k越大,算法的搜索空间也越大.进一步观察发 现,初 始k=100 时,ItrMiner,ItrMinernopt和TKG 的内存消耗都略高,这是因为它们没有设置初始支持度阈值,算法开始的搜索空间较大.然而,在实际应用中,内存是一个重要的限制因素,这方面ItrMiner 表现最佳,它在大多数数据集上的内存消耗最小.相比之下,ItrMinernopt和TKG的内存消耗略高,但总体上它们的内存成本仍然是可以接受的,并且没有一个算法在内存方面显著劣于其他算法.

图6 在六个数据集上k 对各算法内存消耗的的影响Fig.5 The memory consumption of each algorithm with different k on six datasets
4.3.2 实验二:ItrMiner 与Grami 的比较比较ItrMiner 与Grami 的性能,以评估使用ItrMiner进行前k频繁模式挖掘是否达到或超过传统设定支持度阈值的频繁模式挖掘算法的性能.
需要注意,与ItrMiner 在挖掘过程中动态维护兴趣度排名在前k的模式方式不同,Grami 的运行流程主要分三部分:(1)输入支持度阈值;(2)挖掘满足支持度阈值的模式;(3)从模式中选取兴趣度排名在前k的所有模式.为了保证结果的一致性,将不同k的ItrMiner 运行得到的模式集合中的最小支持度作为Grami 的支持度阈值输入.
固定系数α=2.0,在六个真实数据集上,以50 为增量,k从100 增加到300.表4 和表5 分别展示了Grami 和ItrMiner 在六个真实数据集上的实验结果,表中黑体字表示结果最优.

表4 Grami 和ItrMiner 算法在六个数据集上的执行时间(单位:s)Table 4 Execution time (unit:s) of Grami and ItrMiner on six datasets

表5 Grami 和ItrMiner 算法在六个数据集上的内存消耗(单位:GB)Table 5 Memory consumption (unit:GB) of Grami and ItrMiner on six datasets
由表4 可知,在六个真实数据集上,ItrMiner的执行时间比Grami 更短,尤其在YouTube 数据集上,k=300 时Grami 的执行时间接近ItrMiner的四倍.进一步观察,随着k的增大,ItrMiner 的优势更明显.例如,在Amazon 数据集上,k=100时Grami 的执行时间约为ItrMiner 的1.5 倍,而k=300 时,这个比例扩大到3 倍,因为较大的k会导致发现更多的模式,降低模式集合中的最小支持度,这会增大Grami 的搜索空间.而ItrMiner 采用基于兴趣度优先的树模式识别方法,并受到模式扩展约束规则的限制,避免了大量冗余模式的生成,提升了运行效率.然而,在MiCo 和Twitter数据集上,发现ItrMiner 的执行时间比Grami 更长.分析发现,ItrMiner 以动态的方式将潜在的高兴趣度模式扩展出来,在扩展过程中ItrMiner 始终维护前k名的模式,并利用它们产生大量的候选模式,这一过程在特定的数据集上可能会消耗过长的时间.相反,Grami 在开始时就已指定最小支持度阈值,避免生成冗余的低支持度模式.综上,Top-Rank-K 频繁模式挖掘可以在无须设定支持度阈值的情况下更加高效地进行运算.
由表5 可知,除了PDB 和Twitter 数据集外,ItrMiner 在其余数据集上的内存消耗比Grami 更低.这是因为ItrMiner 采用模式扩展约束策略,可以避免生成大量的冗余模式和实例检验,有效地减小了算法的搜索空间.但在PDB 和Twitter 数据集上,ItrMiner 消耗的内存高于Grami,因为ItrMiner 需要同时维护两个队列Sk和Sc,Sk用 于动态存储当前兴趣度排名在前k的模式,Sc用于存储需要通过动态搜索扩展的模式.
实际应用中,用户通常难以确定适当的支持度阈值(参考例1).为此,本文在不同数据集上,对支持度阈值进行调整,并计算k不同时的挖掘任务耗时.表6 展示了运行结果,表中黑体字表示性能最优.由表可见,ItrMiner 在所有数据集上的执行时间均比Grami 更短,并且,随着k的增加,两者之间的差距越大,表明支持度阈值的设定直接影响算法的执行效率.因此,在实际应用中,进行Top-Rank-K 挖掘更加便捷.

表6 Grami 和ItrMiner 算法在六个数据集上的执行时间(单位:s)Table 6 Execution time (unit:s) of Grami and ItrMiner on six datasets
在不同数据集上比较这两种算法的性能表现,验证了ItrMiner 的可行性和实用性,为实际应用中的用户提供更多选择和灵活性,更高效地进行模式挖掘分析.因此,可以将ItrMiner 视为传统频繁模式挖掘的一种有价值的替代方案.
4.3.3 实验三:算法的可扩展性首先,固定系数α=2.0,k=600,将图G=(V,E,L)的规模从(0.1 M,1 M)增长至(1 M,10 M),其中顶点的增量为0.1 M,边的增量为1 M,比较ItrMiner,ItrMinernopt和TKG 的性能,实验结果如图7 所示.由图可见:(1)如前预期,随着图规模的增大,所有算法的执行时间和内存消耗也增加,但由于具体图结构的不同,可能会出现局部下降;(2)与ItrMinernopt和TKG 相 比,ItrMiner 在不同规模的数据集上表现出更短的执行时间和更低的内存消耗.此外,ItrMiner 的执行时间对图规模的敏感度更低,即当图的规模从(0.1 M,1 M)增长至(1 M,10 M),ItrMiner,ItrMinernopt和TKG 的执行时间分别增加了478,885 和705 s.因此,ItrMiner表现了更好的可扩展性.
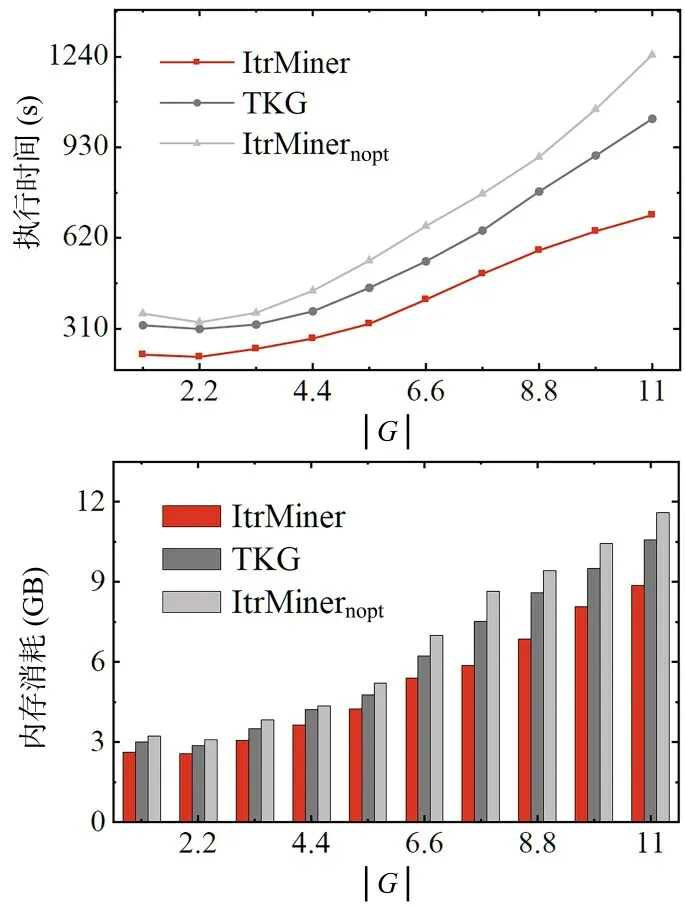
图7 算法的可扩展性Fig.6 Scalability of the algorithms
4.3.4 实验四:α 对算法的影响首先,固定k=200,在六个真实数据集上,α以0.2 的步长从1.6增长至2.6,测试其对ItrMiner 的影响,实验结果如图8 所示.
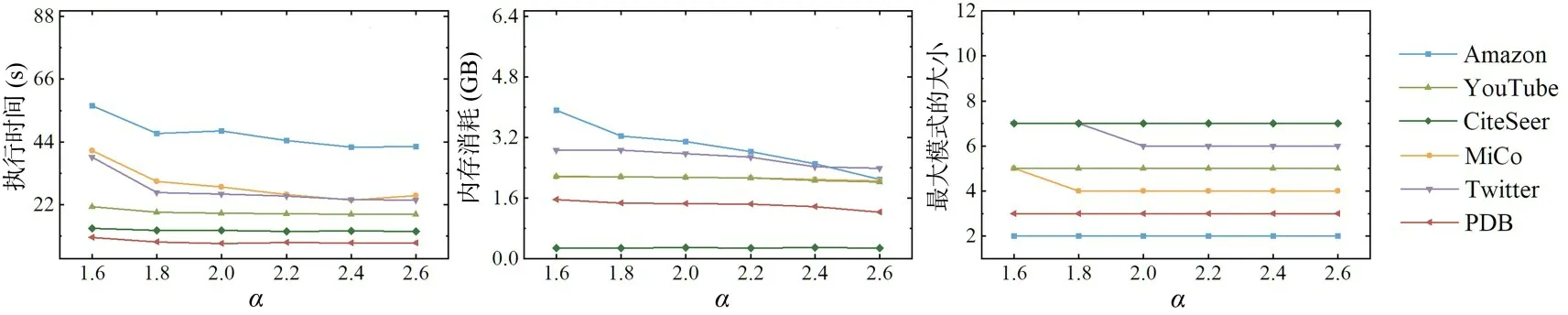
图8 六个数据集上α 对ItrMiner 算法的影响Fig.8 Impact of α of ItrMiner on six datasets
由图可见:(1)随着α的增大,ItrMiner 的执行时间和内存消耗呈下降趋势,因为α越大,兴趣度在支持度上的收益越大,算法会偏向于挖掘支持度更高的模式,从而更快地提高全局的支持度,加快搜索速度;(2)虽然不明显,但是α的增大会使Top-Rank-K 模式的最大模式呈下降趋势.原因同前,基于模式反单调性的特性,子模式的支持度必定不大于父模式,越小的模式支持度一般越高.为了获取更高质量的模式,需要在模式大小和支持度之间寻找平衡,选择合适的α.
5 结论
针对频繁模式挖掘支持度阈值难以设定的问题,本文研究了Top-Rank-K 的频繁模式挖掘问题.首先设计了一项同时考虑模式大小和模式支持度的兴趣度指标,并基于该指标提出一种无须设置初始支持度阈值,直接挖掘排名前k的Top-Rank-K 频繁模式挖掘算法ItrMiner.针对没有初始支持度阈值作为输入、算法剪枝困难的问题,ItrMiner 采用兴趣度优先的树模式识别来快速提升支持度阈值.同时,本文还提出一种新颖的模式扩展约束策略来有效地减少不必要模式的生成,缩短算法的执行时间,降低算法的内存消耗.使用真实图和人工合成图数据集来验证ItrMiner的性能,结果表明,与无扩展约束ItrMinernopt和基线算法TKG 相比,ItrMiner 的执行时间更短,内存消耗更低,在稠密数据集上的优势更显著.另外,通过与带有支持度阈值的Grami 算法的比较,验证了ItrMiner 的可行性和实用性.在人工合成数据集上的实验也证明ItrMiner 具有更好的扩展性.综上,本文提出的ItrMiner 算法,耗时更短,内存消耗更低,还能高效地挖掘兴趣度排名在前k的频繁模式.
未来将致力于解决更大规模图数据的频繁模式挖掘问题,并尝试通过并行计算的方法进一步提高ItrMiner 算法的执行效率.
猜你喜欢
加油站服务指南(2021年4期)2021-07-21
高技术通讯(2021年5期)2021-07-16
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学年刊A辑(中文版)(2020年1期)2020-05-19
数学物理学报(2019年6期)2020-01-13
当代陕西(2019年13期)2019-08-20
数学物理学报(2017年5期)2017-11-23
人生十六七(2015年6期)2015-02-28
测绘科学与工程(2014年5期)2014-02-27
新课程学习·中(2013年3期)2013-06-14
