
多模型融合的时空特征运动想象脑电解码方法
2024-03-24 03:10凌六一李卫校
南京大学学报(自然科学版) 2024年1期
凌六一 ,李卫校 ,冯 彬,2
(1.安徽理工大学电气与信息工程学院,淮南,232001;2.安徽理工大学人工智能学院,淮南,232001)
脑机接口(Brain Computer Interface,BCI)是在人脑与计算机或其他电子设备之间建立的直接交流和控制通道.BCI 作为一种新型尖端技术,有改变世界的潜力且已应用在医疗领域中,能够辅助上下肢功能障碍的患者进行康复训练[1].
脑电图(Electroencephalography,EEG)是一种记录脑电活动的非入侵方式,能够捕获头皮表面脑电的二维数据.EEG 能够以无损人体健康的方式采集,具有表征受试者真实意图的潜力.运动想象(Motor Imagery,MI)是想象人体某躯干部分的运动而非人体躯干实际运动的意识.运动想象脑电图(Motor Imagery Electroencephalogram,MI-EEG)是一种无须外部刺激且能自我调节的脑电图,可以通过电极通道检测,是一种多维的长时间序列点.MI-EEG 的低信噪比、非稳定性和生理伪迹干扰等特点影响MI-EEG 的解码,对BCI的应用带来巨大挑战.因此,从MI-EEG 中提取特征以区分不同想象动作的解码方法是BCI 技术中不可缺少的事项.许多机器学习和深度学习方法已经应用了MI-EEG 的解码,去解决MI-EEG的分类问题.传统的机器学习方法需要依赖专家知识来进行特征提取,而深度学习能够从原始的脑电数据中学习关键和潜在的特征,不需要过度依赖专家知识提取特征.以深度学习的方法来对MI-EEG 解码,通常分为特征输入和非特征输入.特征输入通常使用共空间模式滤波[2]、独立成分分析[3]、短时傅里叶变化和小波变换[4]等具有专家知识的技巧来对原始MI-EEG 进行预处理,将处理后的MI-EEG 作为网络的输入;非特征输入仅使用原始的MI-EEG 作为网络输入.用于MIEEG 的深度学习常用结构包括卷积神经网络(Convolutional Neural Networks,CNN)[5],时间卷积网络(Temporal Convolutional Networks,TCN)[6-7]和transformer 系列等网络[8-9].与传统的机器 学习方法相比,使用深度学习作为MI-EEG 的解码方法,能够以更少的专家知识达到较好的解码性能.Lawhern et al[5]提出一种紧凑的卷积神经网络EEGNet,使用深度卷积和深度可分离卷积来对MI-EEG 进行解码,EEGNet 的提出为MI-EEG 的解码提供了一个很好的思路.Ingolfsson et al[7]提出EEG-TCNet,在EEGNet 的基础上加入TCN网络结构[6],能够提升MI-EEG 的解码准确度,同时EEG-TCNet 的设计使用较少的参数量,能够在资源有限的边缘设备部署.Salami et al[10]提出的EEG-ITCNet 是在EEG-TCNet 的基础上加入Inception 网络结构[11],认为Inception 可以高效 地处理小量的数据集,通过不同卷积核大小,提取不同频率上的时间特征,且使用不同大小的卷积核对MI-EEG 的解码提供了可解释性.Altuwaijri et al[12]提 出MBEEGSE,结 合EEGNet 和Inception网络结构,并在此基础上加入轻量级的SENet[13],能够明确电极通道之间的相互依赖关系,自适应地改变电极通道之间的响应.Zhang et al[14]提出一种基于图的卷积递归注意模型G-CRAM,以探索不同受试者的脑电特征,将电极通道的结点信息嵌入到卷积神经网络中,对MI-EEG 进行解码.Altaheri et al[9]提 出ATCNet,在EEGNet 和TCN 网络基础上加上multi-head attention 来突出MI-EEG 中最有价值的特征,并采用基于卷积的滑动窗口来增强MI-EEG 的解码,能够进一步提升MI-EEG 的解码准确度.上述研究为EEG 的解码开拓了新的研究路线,同时也为以后EEG 的解码提供了研究方向,但仍存在以下问题:传统的解码方法过度依赖专家知识和单一模型的解码方法无法充分发掘脑电信号的潜在信息,导致MIEEG 的解码精度低,限制了BCI 的广泛应用.针对上述问题,本文提出一种多模型融合的时空特征运动想象脑电解码方法(Multi-model Fusion Temporal-spatial Feature Motor Imagery Electroencephalogram Decoding Method,MMFTSF),主要创新性如下:(1)为了不过度依赖专家知识,仅对MI-EEG 进行数值上的预处理;(2)使用多模型融合的网络结构能够提取MI-EEG 不同维度的信息特征;(3)为了充分挖掘多频段脑电信号之间的相关性,嵌入概率稀疏注意力机制使网络自适应地关注与MI 任务相关频段的特征.
1 解码方法
提出的MMFTSF 由六个模块组合:时空卷积网络(Temporal -spatial Convolutional Networks,TSCN)、多头概率稀疏注意力(Multi-head ProbSparse Self-attention,MPS)、时间卷积网络(Temporal Convolutional Networks,TCN)和 全连接层(Fully Connected Layer,FC),并使用基于卷积的滑动窗口(Convolutional-based Sliding Window,SW)和空间信息增强(Spatial Information Enhancement,SIE)来进一步提升解码准确度.
网络整体结构如图1 所示,其中,Channels 表示电极通道数,Time points 表示MI-EEG 的时间采样点信息,LN 表示层归一化(Layer Normalization,LN),#W windows 表示使用W个滑动窗口.将MI-EEG 传入到TSCN,使用三种不同的卷积分别对MI-EEG 的时间、通道和空间进行浅层特征提取,输出具有高维特征的MI-EEG;SW 用来分割MI-EEG,并对每个分割后的MI-EEG 进行LN 操作;使用MPS 注意力机制来关注MI-EEG中最有价值的特征;使用SIE 增强网络空间信息表征能力;TCN 用来提取MI-EEG 中的深层维度特征;最后将经过不同滑动窗口处理后的MIEEG 进行Average,再使用带有softmax 分类器的全连接层FC 进行分类.

图1 网络整体结构Fig.1 Overall network structure
1.1 TSCN 模块TSCN 模块的设计与EEGNet的网络结构相似,能够实现对MI-EEG 浅层时空特征的提取.
将预处理后的脑电数据传入到时空卷积网络TSCN,如图2 所示,将输入的MI-EEG 信号X1∈RC×L扩展维度为X2∈R1×C×L,以图的形式传入网络结构,其中,C为每次实验的电极通道数,L为每次实验的采样点数.将X2传入F1个卷积核大小为(1,Kc)的时间卷积层(Temporal Conv),同时保持输入输出时间维度不变,用于对MI-EEG 时间维度进行滤波,提取浅层时间维度特征,再传入到批归一化层(Batch Normalization,BN)来加速网络训练.之后,将特征图传入到深度为D,卷积核大小为(C,1)的二维深度卷积(Channel DW Conv),提取MI-EEG 不同电极通道间的特征,再经过BN 层加速网络收敛和指数线性单位(Exponential Linear Unit,ELU)激活函数增强网络的非线性拟合能力.将特征图传入大小为(1,P1)的平均池化层(Average Pooling Layer,Avg.Pool)来降维,再将特征图传入F2个卷积核大小为(1,K2)的二维空间卷积(Spatial Conv)来进行时间和通道两个维度的特征融合,再经过BN 层和ELU 激活函数.为了进一步减少特征维度,最后将特征图传入大小为(1,P2)的Avg.Pool.经过TSCN 块之后,MI-EEG 的输出维度为X3∈RF2×Tc,其中,Tc=L/P1/P2.输出特征图中每个数值都包含原始MI-EEG 的C×P1×P2采样点信息.

图2 时空卷积网络Fig.2 Temporal-spatial convolutional networks
1.2 SWSW 是基于对脑电信号分割预处理的思想,通过对原始信号进行分割来弥补数据不足的缺陷,同时使用SW 也是对MI-EEG 部分信号的恒等变换.使用基于卷积的滑动窗口能够提升MI-EEG 的解码,并且,在实施过程中不会增加权重参数,只需使用一个不进行卷积操作的滑动窗口就可以实现对MI-EEG 的分割和恒等变换.
将TSCN 块的输出特征图X3在时间维度上使用一个长度为Tw,步长为1 的卷积滑动窗口SW 进行切分,假设滑动窗口的数量为W,相对应的Tw应满足Tw=Tc-W+1,经过SW 输出的特征图X4∈RF2×Tw,在下文会通过实验证明使用一个合适的滑动窗口能够有效增加MI-EEG 的解码准确度.将SW 输出的特征图X4传入到LN 对时间序列长度Tw进行层归一化处理得到特征图X5∈RF2×Tw.
1.3 MPS 模块为了模仿人能够在眼球视角范围内聚焦在关键的区域,在设计解码方法过程中,需要对不同区域的特征设置不同的权重系数来拟合对不同区域的重视程度.在深度学习中,网络模型能够自适应地调整不同区域的权重系数称为注意力机制.对于MI-EEG 的时间序列,本身包含不同频段的时间特征,对不同的频段采用相同的关注程度会降低对脑电信号的解码性能,使用注意力机制能够使网络自适应地关注与MI 相关的频段特征.在本次实验过程中采用的注意力机制为Informer[15]中的多头概率稀疏注意力机制MPS,MPS 的提出主要是为了解决使用transform[8]中Muti-head Attention 存在计算成本高和对时间序列问题预测能力较弱的问题.
将输入数据X5经过三个不同的权重矩阵Wq,Wk,Wv产生相应的查询(Query)向量Q∈Rd×Tw、键(Key)向量K∈Rd×Tw和值(Value)向量V∈Rd×Tw.qi,ki,vi分别代表Q,K,V中的第i行向量,d表示每个headi的维度.概率稀疏自注意力机制如图3 所示,随机采样S1个ki向量组成K1,其中S1=min(ceil(M×lnTw),Tw),M决定了S1的值,表示从向量K中选择行向量的个数;计算每 个qi向量 与K1矩阵的稀疏性M(qi,K)得分,M 表示每个qi向量与K1矩阵产生注意力的函数.
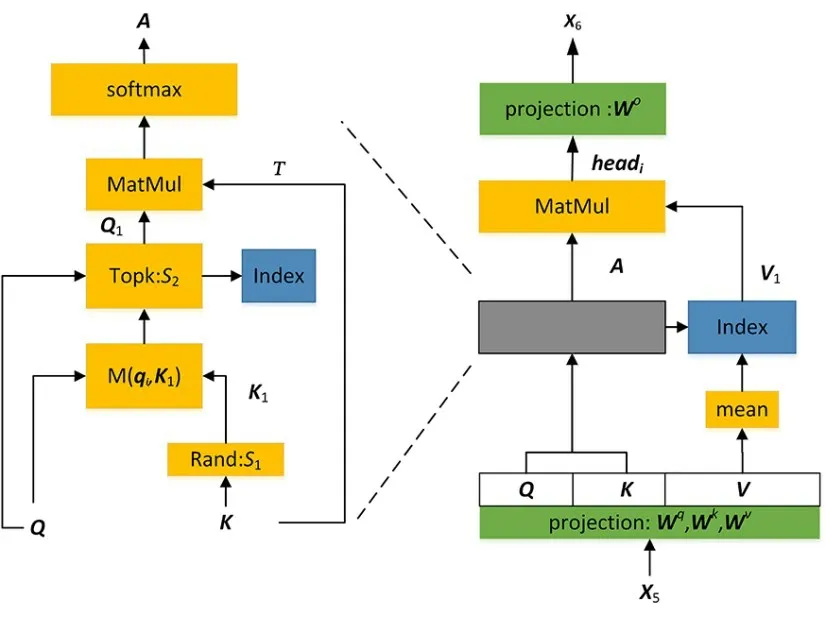
图3 概率稀疏自注意力机制Fig.3 Probsparse self-attention mechanism
选择稀疏性得分最高的S2个qi组成矩阵Q1,对应的索引为 Index,其中,S2=min(ceil(N×lnTw),Tw);将V矩阵在时间序 列维度上取平均组成矩阵V1,V1矩阵的计算只在Index 部分进行;计算出每个headi的Attention;将每个headi进行拼接,再通过权重矩阵映射输出X6∈RF2×Tw.上述过程如式(1)~(7)所示.
1.4 SIE 模块在实验过程中,使用注意力机制自适应调整权重系数的网络模型往往关注不同空间区域的信息特征,但对通道信息和通道与空间之间的信息具有较弱的表征能力,因此,在使用注意力机制的网络模型中需要加上一个能增强网络空间信息表征能力的网络模型.
将MPS 输出的特征图X6进行信息增强,SIE是由卷积核大小为Kk的一维卷积、BN 和ELU 激活函数实现,输出X7∈RF2×Tw.
将特征图X5经过多头概率稀疏自注意力机制和空间信息增强SIE 处理生成的特征图X7进行相加操作,得到X8来作为TCN 模块的输入.
1.5 TCN 模块TCN 模块的设计包含两个残差块,与TCNet 的网络结构相似,将TCNet 的ReLU 激活函数改为ELU 激活函数.每个残差块都有两个扩张因果卷积(Dilated Causal Conv,DCC),每个DCC 后都加入BN 层和ELU 激活函数.扩张因果卷积的提出是为了满足时序问题中某一时刻的输出只依赖于当前和历史时刻输入的需求,同时使用扩张因果卷积能够实现指数级增加感受野(Receptive Field Size,RFS).
其中,KT是扩张因果卷积的大小,L表示堆叠残层数.为了利用所有的序列点,KT和L的选择,应满足RFS≥Tw.
TCN 的结构如图4 所示,特征图X8经过两个残差连接的因果卷积,其中前一个残差的扩张因果卷积的数量为Ft,卷积核大小为K1,扩张率为D1,后一个残差的扩张因果卷积的数量为Ft,卷积核大小为K2,扩张率为D2.为了加速网络收敛和增强网络的非线性拟合能力,在每个卷积后面都加上BN 和ELU 激活函数,经过TCN 输出为X9∈RFt×1.

图4 时间卷积网络Fig.4 Temporal convolutional networks
将TCN 的输出特征图X9输入全连接层FC ∈RFt×n_class,输出特征图为X10∈Rn_class.每个滑动窗口分割后的特征图进行LN,MPS,SIE,TCN 和FC 之后生成一个X10,将这W个滑动窗口所产生的特征图拼接成X11∈Rw×n_class,再进行平均和softmax 分类器处理,最终生成X12∈Rn_class来进行分类,其中n_class 为类别数.以上网络的超参数选择如表1 所示.
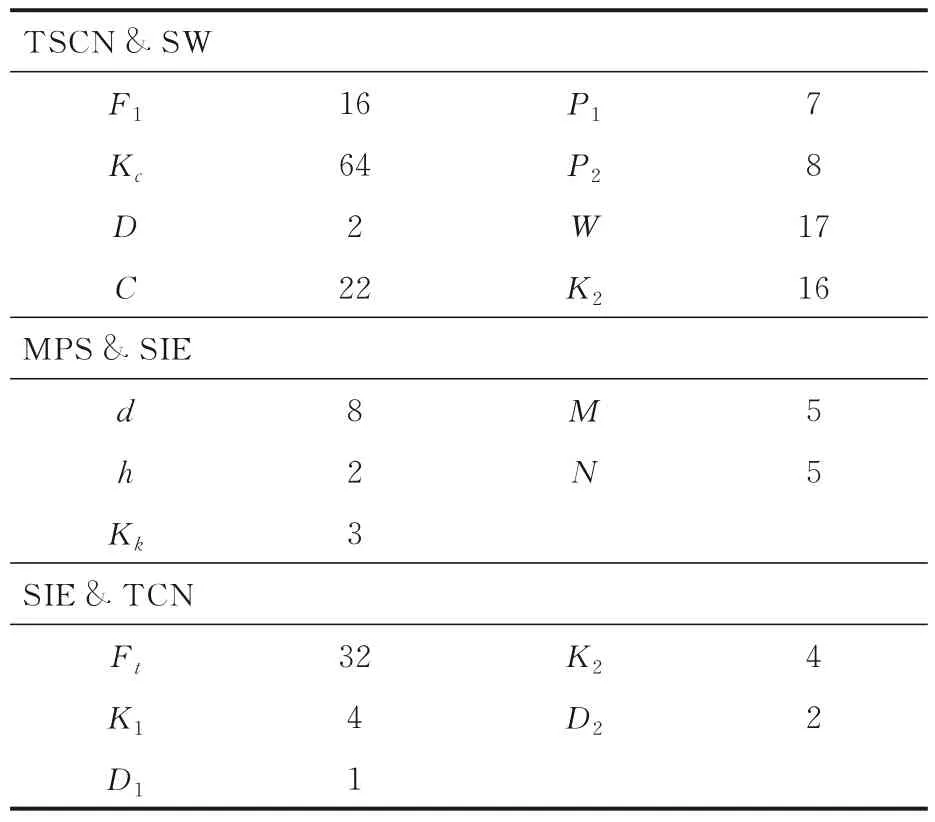
表1 超参数设定Table 1 Hyperparameter setting
2 实验结果与分析
2.1 数据集介绍与预处理实验采用2008 年第四次国际BCI 竞赛运动想象的脑电数据集BCI IV-2a.该数据集包含九名被试者,编号为A01~A09,每个被试者进行两次sessions,将其中一个session 作为训练集,另一个session 作为测试集;每次实验的标签为想象左手运动、想象右手运动、想象双脚运动和想象舌头运动(简称left hand,right hand,feet,tongue)中的一种,每种MI进行72 次,所以每个受试者在每个session 进行288 次MI 实验.BCI IV-2a 以250 Hz 采样率采集MI-EEG 数据,同时进行0.5~100 Hz 的带通滤波和50 Hz 的凹陷滤波的预处理.本实验选择22 个EEG 电极通道,每次实验选择MI 结束时前4.5 s,共 计1125 个采样点,即n_class=4,C=22,L=1125.在对原始MI-EEG 进行预处理时,没有使用共空间模式滤波[2]、独立成分分析[3]、短时傅里叶变化和小波变换[4]等具有专家知识的处理方法,也没有剔除被专家标记为伪迹的实验数据,仅对每次实验的每个通道进行标准差标准化,使处理后的数据符合标准正态分布,即均值为0,方差为1 的数据分布,如式(11)所示:
其中,xt,j,i表示原始MI-EEG 第t次实验、第j个 通道、第i个时间的采样点数值;ut,j表示第t次实验、第j个通道的均值;σt,j表示第t次实验、第j个通道的标准差;x′t,j,i表示经过数值处理之后的第t次实验、第j个通道、第i个时间的采样点数值.
2.2 训练过程操作系统为Windows 10,通过PyTorch 框架搭建网络结构,在Pycharm 进行代码实验,GPU 为GTX 3060 12 GB.使用Adam 优化器、交叉熵损失函数,迭代1000 次.为了防止过拟合,若300 次迭代准确度无变化即停止训练,权重损失率设置为0.001,初始学习率为0.001,学习率更新方式为余弦退火函数.
2.3 消融实验网络结构决定了解码性能的上限,选择一组最优的超参数能够逼近解码上限.
2.3.1 滑动窗口数量对解码性能的影响经过TSCN 模块输出的X3的时间序列长度为Tc,每个时间点都包含着原始MI-EEG 的C×P1×P2采样点信息,每个时间点都包含原始MI-EEG 的高维特征.因此,对MI-EEG 的分割方式直接影响解码性能,使用滑动窗口对X3进行分割,不同大小的滑动窗口表示对原始MI-EEG 的高维时间特征不同的聚合方式.经过长度为Tw的滑动窗口输出的特征图,每个特征点都包含着原始信号C×P1×P2×Tw时间点信息.
为了验证滑动窗口的数量W对MI-EEG 的解码性能的影响,W在[]1,Tc-1 之间取值,在M=N=5 和M=N=1 的条件下,进行仿真验证,如图5 所示.其中,W=1 可以理解为不加滑动窗口.由图可见,增加滑动窗口的数量能够明显地提升MI-EEG 的解码性能,仅使用两个滑动窗口(W=2)比不加滑动窗口(W=1)在MIEEG 解码准确度提升4%以上,同时设置一个合适的滑动数量,进一步提升解码准确度,在本次实验中,当W=17 时,解码准确度最高.

图5 滑动窗口数量对解码准确度的影响Fig.5 Effect of the number of sliding windows on decoding accuracy
2.3.2 MPS 中点积数量对解码性能的影响Informer[15]在利用点积对去产生注意力机制的过程中,并非所有的点积对都能够产生有效的注意力机制.使用不同的点积数量对MI-EEG 进行解码,在W=1(Tw=20)和W=5(Tw=16)的情况下,M(N)的取值分别为{1,2,3,4,5,6,7}和{1,2,3,4,5,6}.
表2 为在W=1 和W=5 的情况下,使用不同的点积数量对MI-EEG 解码准确度的影响.由表可见,使用更多的点积对并没有对解码性能产生有效的影响,甚至还会有损解码性能.并且使用更少的点积对可以在一定程度上缓解内存的计算负担,因此使用MPS 更适合对长时间序列的脑电信号进行解码.

表2 点积数量对解码准确度的影响Table 2 Effect of the number of dot product on decoding accuracy
2.3.3 SIE 对解码性能的影响SIE 的提出是为了解决使用点积对产生注意力机制的解码方法在时序问题上具有较弱的空间信息表征能力的问题.SIE 在网络结构上仅有一个卷积,但是对MIEEG 的解码性能具有非常明显的效果,同时,仅增加一个卷积不会对网络的参数量和内存的浮点运算造成太大的影响.为了验证增加SIE 是否能够影响MI-EEG 的解码,进行以下的实验:
(1)在ATCNet 的基础上加上SIE 来对MIEEG 测试,记为ATCNet+SIE;
(2)在MMFTSF 的基础上减去SIE 来对MIEEG 进行测试,记为MMFTSF-SIE.
表3 展示了不同方法的解码准确度,由表可见,在ATCNet 的基础上加上SIE 模型,准确度可提升1.68%,同时SIE 对所提解码方法有1.07%的提升,证明增加SIE 模块能够有效地提升MIEEG 的解码准确度.

表3 SIE 对解码准确度的影响Table 3 Effect of SIE on decoding accuracy
3 与其他方法的实验对比
为了验证MMFTSF 对MI-EEG 解码的高效性,选用近年以深度学习为框架对BCI IV-2a 解码的现有技术与本次实验进行对照,实验数据如表4 所示,表中黑体字表示结果最优.表4 中数据并非原论文对BCI IV-2a 数据集的解码准确度,而是通过论文中所提出的解码方法在本实验环境下所取得的准确度,即不改变现有技术中解码方法中的超参数,使用本次实验的预处理和训练过程得到的结果.由表可见,MMFTSF 在MI-EEG解码中已经明显优于现有技术,并且每个受试者的解码准确度都有增强,和ATCNet 相比,对受试者A01,A02,A04,A06,A08,A09 的解码准确度能提升4%以上,也具有更强的泛化性.

表4 与其他已复现方法的解码准确度比较Table 4 Decoding accuracy comparison with other reproduced methods
图6 为MMFTSF 在受试者A01,A03,A07,A09 测试集上所体现的混淆矩阵.与ATCNet,EEG-TCNet 和EEGNet 相比,MMFTSF 在受试者上解码性能最优,解码准确度分别提升3.55%,7.67% 和13.34%.图7 为MMFTSF 对数据集的混淆矩阵,图8~10 分别为ATCNet,EEG-TCNet 和EEGNet 对数据集的混淆矩阵,对比不同方法的混淆矩阵.可以看出,MMFTSF 对每种运动想象类别具有更高的解码性能,并且更具有鲁棒性.从单个和整体受试者的解码准确度和每种运动想象的解码性能角度上分析,MMFTSF 的解码准确度优于现有技术.

图6 A01,A03,A07 和A09 受试者的混淆矩阵Fig.6 Confusion matrix for subjects A01,A03,A07 and A09

图7 MMFTSF 对BCI IV-2a 的平均混淆矩阵Fig.7 Average confusion matrices of MMFTSF for BCI IV-2a

图8 ATCNet 对BCI IV-2a 的平均混淆矩阵Fig.8 Average confusion matrices of ATCNet for BCI IV-2a

图9 EEG-TCNet 对BCI IV-2a 的平均混淆矩阵Fig.9 Average confusion matrices of EEG-TCNet for BCI IV-2a

图10 EEGNet 对BCI IV-2a 的平均混淆矩阵Fig.10 Average confusion matrices of EEGNet for BCI IV-2a
为了进一步说明MMFTSF 具有更高的解码性能,表5 展示了不同方法对BCI IV-2a 数据集的解码准确度,由表可见,MMFTSF 具有更高的解码准确度.在MI-EEG 解码任务中,G-CRAM 以图的卷积递归注意模型作为解码方法;MCNN 是使用多层CNN 融合的解码方法;MSFBCNN 是一种嵌入Inception 的并行多尺度滤波器组CNN解码方法;EEG-ITNet 先使用Inception 并行处理,再通过TCNet 进行特征提取的解码方法;MSAMF 是在多尺度融合CNN 的基础上加入注意力机制SENet 的解码方法;MBEEGSE 是一种使用多分支CNN 的解码方法,每个分支包含EEGNet和SENet 注意力机制;TCACNet 是一种使用时间注意力来识别与MI 任务相关的时间片和空间注意力机制自适应地调整每个通道的权重系数的解码方法.上述网络中G-CRAM 属于单一的图卷积网络模型,MCNN,MSFBCNN,EEG-ITNet,MS-AMF,MBEEGSE 和TCACNet 等是使用CNN 及其变体(DCC)组成不同网络结构的解码方法,也属于单一模型,而MMFTSF 是CNN,DCC 和Informer 融合的解码方法,以CNN 为单位的时空卷积网络提取MI-EEG 中浅层信息特征,使用Informer 中多头概率稀疏自注意力机制使网络自适应地关注与MI 任务相关频段的特征,使用CNN 和DCC 结合的TCN 结构提取MIEEG 高维时间特征,同时使用基于卷积的滑动窗口和以CNN 为单位的空间信息增强模块进一步提升MI-EEG 解码准确度,是一种多模型融合的解码方法,多模型融合的解码方法能够提取MIEEG 不同维度的信息特征,进而提高解码准确度.
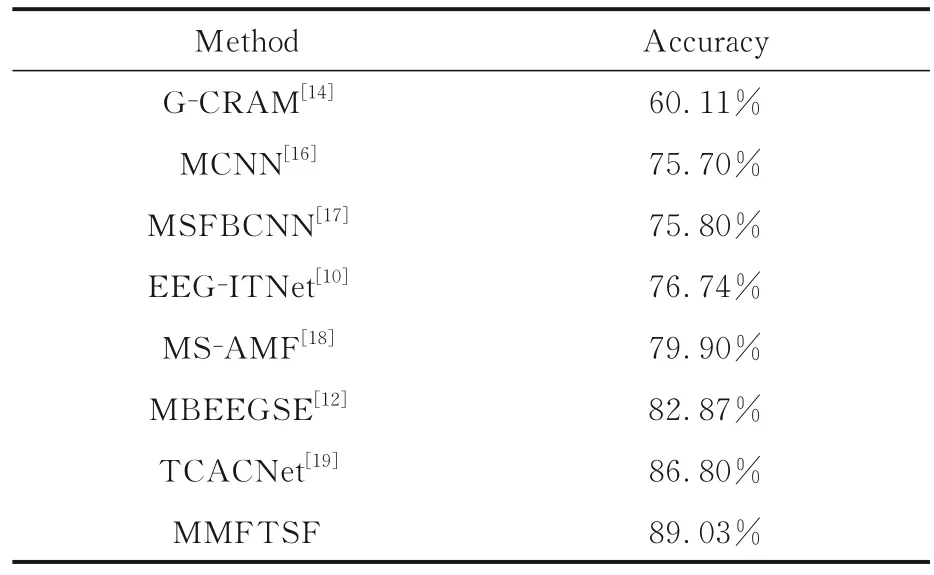
表5 不同方法对BCI IV-2a 的解码准确度Table 5 Decoding accuracy of different methods on BCI IV-2a
4 结论
现有技术对MI-EEG 低效的解码性能和对MI-EEG 过度依赖预处理的方式限制了BCI 的广泛发展,提出一个多模型融合的时空特征运动想象脑电解码方法.先通过TSCN,使用不同的卷积操作对MI-EEG 的各个维度进行浅层特征提取,再使用MPS 关注MI 任务中最有价值的特征,再经过TCN 来提取MI-EEG 中的高级特征,最后使用带有softmax 分类器的全连接层进行分类.同时使用基于卷积的滑动窗口和空间信息增强来提升解码性能.实验结果证明MMFTSF 能够在BCI IV-2a 数据集上达到89.03%的解码准确度,相比于ATCNet,EEG-TCNet 和EEGNet,分 别提升3.55%,7.67%和13.34%.此外,为了验证SW 中滑动窗口的数量、MPS 中点积数量对和使用SIE 模块对MI-EEG 解码性能的影响,通过大量实验证明,适当增加滑动窗口的数量能够大幅度地提升解码性能,只需较少的点积数量对就能实现较好的解码性能和增加SIE 模块能够提升解码准确度.同时,只对MI-EEG 做数值上的简单预处理,选择所有实验数据,因此,本实验过程并没有使用过多的专家知识.通过上述实验数据,说明MMFTSF 优于现有技术,能够对BCI 的应用做出一定贡献.然而,多模型融合网络结构虽然比单一模型的解码性能更有优势,但是,多模型融合会带来计算复杂度,造成推理时间过长的问题,因此在之后的工作中,会利用知识蒸馏的方法,设计一个多模型轻量化网络来对MI-EEG 进行解码.
猜你喜欢
中国石油石化(2022年12期)2022-07-16
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
制造技术与机床(2018年11期)2018-11-23
建筑科技(2018年6期)2018-08-30
意林(绘英语)(2018年1期)2018-04-28
中国交通信息化(2016年5期)2016-06-06
城市轨道交通研究(2015年11期)2015-02-27
雷达学报(2014年4期)2014-04-23
