
知识情境感知的深度知识追踪模型
2024-03-24 03:10张所娟陈卫卫
南京大学学报(自然科学版) 2024年1期
蒲 杰,张所娟,陈卫卫
(陆军工程大学指挥控制工程学院,南京,210023)
随着互联网和移动通信技术的普及,在线教育正以前所未有的规模发展[1].学习者在使用在线教育系统(如Massive Open Online Course,MOOC)时产生了大量学习者与学习系统之间的交互数据,而知识追踪(Knowledge Tracing,KT)就是从这些交互数据中挖掘学习者动态的认知状态、学习偏好等信息的一类认知诊断技术[2].
学习者在学习过程中,通过对具体试题的作答,按照作答顺序产生一连串的交互记录.知识追踪任务的目标是通过有监督学习的方法来评估学习者在作答过程中认知状态的变化,并预测其在下一个时刻的答题情况.本文提出结合知识权重、试题难度等知识情境实现知识追踪,如图1 所示,进一步为在线教育系统提供评估支持,使每个学习者都能获得更优的学习体验.

图1 融合知识权重的知识追踪示意图Fig.1 The example of the knowledge tracing with incorporated knowledge weights
知识追踪模型通常分三类:基于概率图模型的知识追踪、基于因素分析的知识追踪和基于深度学习的知识追踪[3].基于概率图模型和因素分析的知识追踪方法对建模学习者的认知状态具有较好的解释性,但很难捕捉复杂的认知过程.相比之下,基于深度学习的知识追踪模型依赖于深度学习对特征提取的强大能力,近年来成为研究的热点.许多学者提出了一系列基于深度学习的知识追踪模型,其中最具代表性的是深度知识追踪(Deep Knowledge Tracing,DKT)[4].
早期KT 模型通常将试题编号或试题包含的知识点编号以独热(one-hot)编码作为模型输入.研究表明,使用知识点编号作为输入的模型,其性能优于使用试题编号作为输入的模型[5].而且,如果考虑答题过程中学习者与试题之间更复杂的交互关系,如知识点间的关联关系[6]、知识点难度[7]等,能使模型的性能进一步得到提升.
现有的知识追踪方法通常直接利用试题中考查的知识点来表征试题,这样会损失重要的知识情境特征,限制模型的效果.联通主义理论认为知识建构于情境之中,教育强调学习内容紧贴实际背景,即情境(Context)的融入.然而,目前对于学习者状态的评估主要关注纯粹的知识,试题之间互相独立,缺乏与现实世界的联系,无法考查学习者在面对实际任务时的能力和表现.同时,在基础教育阶段,学习者的信息素养评测考查的是学习者应对各种复杂现实情境、利用信息解决现实任务的能力,如果忽视试题内在的知识情境,就无法有效地评估学习者认知状态的发展情况.因此,本文将试题涉及的各知识点的权重,试题的难度、区分度以及试题本身的猜测和失误因子看作试题包含的知识情境.
同时,与静态的认知诊断模型相比,传统知识追踪模型在解释性方面稍显不足.认知诊断模型源自教育学和心理测量学,并将教育理论的影响因素纳入模型设计.在知识追踪模型中引入认知诊断模型蕴含的教育理论特性,可以增强对学习者认知过程的理解,提升解释性.
本文提出一种新的知识追踪模型,即知识情境感知的深度知识追踪模型(Knowledge Context-Aware Deep Knowledge Tracing Model,KCA -DKT),其融合知识情境特征来增强试题的表征,结合学习者的回答情况,利用循环神经网络对学习者的认知状态进行建模,同时,引入知识权重来实现多个知识聚合,最后由模型预测层对学习者未来的答题表现进行初步预测,并引入失误、猜测因素修正预测结果.该模型一方面融入知识情境特征,进一步丰富试题信息,提高序列建模效果;另一方面利用认知诊断模型所蕴含的教育理论特性,强化知识追踪的可解释性.本文的创新如下.
(1)实现了对试题内部知识之间的交互关系带来的知识权重的表征.
(2)构建融合知识权重、试题难度等信息的知识情境嵌入模块来增强模型的试题表征.
(3)利用认知诊断模型蕴含的教育理论特性增加知识追踪模型的可解释性.
1 相关工作
1.1 知识情境
1.1.1 知识权重由于学习目标的差异性,不同的试题中知识间往往呈现不同的交互关系,不同的知识对任务达成的重要程度也不同.学习过程中某些知识点在解决问题时比其他知识点更关键[8-9],即每个知识点的权重可能是不同的[10].尽管部分学者已经开始考虑多知识间的相互影响,但现有的研究仅从知识自身的层次结构或者学科体系中的知识依赖关系来分析确定知识间的关联性,没有结合试题本身来建模知识关联.若忽视同一试题中不同知识之间的影响,对学习者认知过程的理解会产生一定的偏差.
现有的知识追踪方法主要捕捉基于学科体系的知识关联,这类知识关联可以看作是相对静态和稳定的.其中,知识先决关系的研究受到了特别关注[6,11],如关系感知知识追踪(Relation-Aware Self-Attention Model for Knowledge Tracing,RKT)[12]通过自注意力感知试题的上下文信息来获得试题之间的相关关系;注意力知识追踪(Attentive Knowledge Tracing,AKT)[13]则利用多头注意力,用不同的时间尺度对应不同的衰减率来感知过去试题和当前试题的交互关系.
然而,现有研究大多将包含两个(含)以上知识点的试题中的知识点视为同等重要,这是一种简化,虽然降低了模型处理的复杂性,但实际上不同知识点对于作答当前试题的重要程度不尽相同.因此,在多知识点试题中,每个知识点的权重可能是不一样的.
1.1.2 试题难度难度(Difficulty)是用来描述试题的重要参数之一,试题中除了知识点之外,还有任务难度等其他特征.项目反应理论模型(Item Response Theory,IRT)[14]包含难度参数,其对应的数值越大,试题越难.难度通常被定义为一个试题被正确回答的概率,通过统计分析可以得到难度参数的估计值.试题的难度系数可以由专家设置,也可以通过学习者的学习表现与试题之间的交互来捕捉.将试题的难度系数纳入知识情境的范畴可以更好地表征试题,更精准地评估学习者认知状态.
本文把试题内部各知识权重、试题的难度系数作为面向试题知识情境的表征信息.
1.2 知识追踪下面分别介绍基于概率图模型的知识追踪、基于因素分析的知识追踪和深度学习知识追踪.
1.2.1 基于概率图模型的知识追踪概率图模型用图形和概率分布表示变量之间的关系[15],贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)是一种具有代表性的基于概率图的知识追踪模型[2].BKT 将学习者的认知状态建模为一个动态变化的过程,基于先验概率(通常根据领域专家的经验或大量数据得出)和学习者的历史答题记录,通过隐马尔可夫模型(Hidden Markov Model,HMM)来推测学习者的知识水平和理解程度.在BKT 模型的基础上,许多研究者提出了相应的变体模型.例如,Käser et al[16]对知识点之间的关系和多个包含多个知识点的试题进行建模,Khajah et al[17]在BKT 模型中引入猜测概率和失误概率,Yudelson et al[18]将学习者特定参数和技能特定参数作为BKT 模型的参数.
基于概率图的知识追踪模型对于建模学习者的认知状态有较好的解释性,但模型的结构通常基于统计学原理进行设计,模型参数需要通过复杂的推导算法来确定.而且,由于认知过程的复杂性,这些模型可能难以完全捕捉学习者的认知过程.
1.2.2 基于因素分析的知识追踪基于因素分析的知识追踪模型通过学习一个回归函数并结合学习者在具体学习过程中的各种因素来拟合并预计学习者的表现,代表性模型包括项目反应理论模型(IRT)[14]、表现因素分析模型(Performance Factor Analysis,PFA)[19]和因子分解机知识追踪模 型(Knowledge Tracing Machine,KTM)[20].IRT 模型考虑了试题的特征因素(如难度和区分度),通过建立逻辑函数来推断学习者的潜在能力水平.PFA 模型区分学习者在作答试题时答对和答错的不同情况,设置相应的学习率.KTM 模型综合考虑了学习者、试题、知识点、答对或答错次数等多种因素进行建模.
基于因素分析的知识追踪模型没有考虑学习者回答问题的先后顺序,在一定程度上弱化了问题的处理难度.然而,这也导致了一个假设,即特定学习者的能力水平始终保持不变,这与教育学理论和实际情况不相符.
1.2.3 深度学习知识追踪由于循环神经网络(Recurrent Neural Networks,RNN)在图像处理、自然语言处理等任务上取得了较好的效果,DKT[4]首次将RNN 应用于知识追踪模型.随后有大量的相关研究,如基于图的知识追踪(Graph-based Knowledge Tracing,GKT)[21]使用图神经网络来模拟知识概念的结构图和学习者知识状态的变化过程;动态键值对记忆网络知识追踪(Dynamic Key-Value Memory Networks,DKVMN)[22]使用一个静态矩阵存储知识概念,使用另一个动态矩阵存储和更新相应知识概念的掌握水平;AKT[13]使用单调注意力机制,将预测学习者对评估试题的作答与他们过去的历史答题记录联系起来.
深度学习知识追踪模型在具体任务上取得了较好的效果,但由于深度学习的复杂网络结构和黑盒性质,深度学习知识追踪模型的可解释性差,给后续研究和应用带来困难.本研究引入知识情境以及认知诊断模型中的猜测和失误因子,进一步增强知识追踪方法的可解释性,为学习者画像、学习推荐等下游任务提供有效的支撑.
2 模型与方法
本文提出KCA-DKT 模型,其框架如图2 所示.本节首先介绍必要的假设及知识追踪的问题,然后分别介绍知识情境嵌入模块、知识状态追踪模块、知识聚合计算模块、学习表现预测模块.

图2 知识情境感知的深度知识追踪模型框架图Fig.2 The framework of knowledge context-aware deep knowledge tracing model
2.1 问题描述
假设1若一道试题对应多个知识,则知识之间存在不同的交互关系.
假设2考虑同一试题内知识间的交互关系,各知识对于试题正确作答的支持力度不同,称为知识权重.
假设3由试题考查的知识概念及对应交互关系带来的知识权重和试题本身的难度系数,共同构成知识情境.
学习系统中有N个学习者、M道试题和K个知识概念,分别表示为:
学习者sn的答题历史记录定义为:
2.2 知识情境嵌入模块对于试题,除了考查的知识概念不同,试题内不同知识概念的重要性也存在差异,这种差异由试题内多个知识存在的交互关系产生,因此,在构建知识情境特征时,首先应考虑知识权重的表征方法.在认知诊断模型中使用Q矩阵建立试题与知识概念之间的关联,试题ei与知识点kj相关时Qij=1,不相关时Qij=0.本节首先引入Q矩阵,可知t时刻试题对应的知识概念.
初始化知识权重参数矩阵如式(1)所示:
其中,wt=1/Ket表示t时刻对应试题的知识权重参数,符号◦表示逐个元素相乘.
其次,在试题表征中嵌入知识权重,具体方法如下.首先,将学习者sn在t时刻作答的试题表征为涉及各知识权重的向量,如式(2)所示:
根据Q矩阵给出的知识关联信息,非0 部分反映该试题考查的知识,在保留Q矩阵信息的前提下,知识权重向量在训练过程中按照式(3)进行约束,归一化处理为:
归一化处理后,每道试题考查的知识概念的向量元素和为1,如式(4)所示:
根据假设3,融合试题难度系数来实现知识情境特征的构建.采用统计的方式[23]计算每个试题的难度系数,学习者sn在t时刻做的试题的难度系数为,如式(5)所示:
其中,count()* 表示满足条件*的数量;试题的难度系数是训练集的所有答题记录R中试题答错的次数与作答次数的比值.由于试题层级数据的稀疏性,当式(5)计算的试题难度系数时,用相同的统计方法计算每个知识点的难度,试题难度按对应知识点难度的平均值计算.
其中,Wkd∈RK×()K+1,是模型训练学习的参数,⊕为串联操作.
其中,0={0}1*K表示维度为K的全0 向量.
2.3 认知状态追踪模块本模块以知识情境嵌入模块得到的试题表征向量作为输入,利用门控循环单元(Gate Recurrent Unit,GRU)中隐藏状态向量的变化情况来模拟学习者sn的隐式认知状态随特定试题作答后的变化情况.具体步骤如下.
其中,σ表示Sigmoid 激活函数,Wir,Whr,Wiz,Whz∈RD1×2K和br,bz∈RD1×1是模型训练要学习的参数.
由于学习者在学习过程中存在遗忘行为,根据式(10)模拟计算遗忘历史隐式认知状态中的部分信息,得到候选激活门向量:
其中,tanh 为激活函数,Wih,Wh∈RD1×1和bh∈RD1×1是模型训练要学习的参数,◦为逐个元素相乘.
2.4 知识聚合计算模块在认知状态追踪模块中可以获得学习者sn在t时刻的隐式认知状态,通过全连接层建立隐式认知状态到知识维度的显式认知状态的关联关系:
其中,W1∈RD1×K和b1∈RK×1是模型训练要学习的参数.
对于多知识点的试题,学习者是否达成某项试题取决于其在各知识点的显式认知状态以及该知识点的权重.如学习者sn在t时刻的显式认知状态=[0.2,0.3,0.4,0.1],若t+1 时刻对应的试题考查第1,3,4 个知识点,该任务中各知识点的权重分别为=[0.2,0.1,0.7].参考认知诊断模型对于多知识任务的处理方式,学习者在特定试题上的能力可以表示为表示聚合函数,即聚合每个知识点的显式认知状态来获得达成试题的能力值.本文将聚合函数设置为知识权重与显式认知状态的加权计算,得到t时刻学习者sn在试题上的能力值具体计算如下:
其中,Σ 表示对向量进行逐元素求和.
2.5 学习表现预测模块由式(14)计算t+1 时刻作答任务的区分度:
其中,C∈RM×1是模型训练要学习的参数.
通过两个全连接层和一个输出层得到理想作答情况下(即不考虑猜测和失误的情况)的预测结果:
在预测学习表现时应考虑学习者在答题过程中的猜测和失误行为.试题的猜测因子表示在学习者没有掌握正确作答试题所需知识点的情况下,以猜测的方式答对试题的概率,取值范围通常是0~1,其值越高说明学习者更可能通过猜测来正确作答.试题的失误因子表示学习者在认知状态完全掌握所需知识点的情况下,出现失误而答错的概率,取值范围通常为0~1,其值较高表示学习者更容易出现失误.本文在KCA-DKT 模型中加入了猜测和失误因子,进一步提高了模型的预测性能和可解释性.
其中,W5,W6∈RM×1是模型训练需要学习的参数.
3 实验结果分析
3.1 实验设置使用ASSIST2009[24]和Algebra2006[25]两个公开数据集及一个私有数据集Program 进行实验.
ASSIST2009 数据集是ASSISTments 在线教学系统收集的数据集,涉及的试题对应一个或多个知识等多种情况,选择更新的skill-builder 版本,该版本修复了部分数据重复的问题.
Algebra2006 是PSLC DataShop 发布的数据集,是KDD Cup 2010 竞赛的数据集之一.KDD Cup 中包含多个步骤的任务,将一个含多个步骤的问题按照步骤看作多个不同的试题,数据集中的每一条响应日志都包含一个学习者对一个问题的一个步骤的回答结果.
选取在线编程学习平台产生的真实数据集Program,学习者可以在线进行编程学习,提交答案并实时获得编译器输出进行修正.平台允许学习者多次重复作答,本文选取学习者前两次的作答记录以保证实验的公平性.
对于两个公开数据集的预处理,均删除了未标记知识点的试题和总计作答次数小于15 的试题.同时,将单个学习者作答次数大于200 的序列划分为多个最大长度为200 的作答序列,删除总计作答次数小于15 的学习者.预处理后的响应序列的20%为测试集,剩下的数据再按8∶2 分为训练集和验证集.Program 数据集通过正则表达式提取含关键字python 的试题,将试题按照作答次数从高到低排序,取作答次数多的前70 题,平均作答次数大于200.三个数据集预处理后的情况如表1 所示.

表1 预处理后的数据集的统计信息Table 1
本文基于Pytorch 深度学习框架实现KCADKT.为了保证实验的公平性,所有基准模型的参数均调整至最优性能.
实验环境:两个2.1 GHz Intel(R)Xeon(R)Gold 6230R CPU 和一个11 GB GeForce RTX 2080Ti GPU 的Linux 服务器.
3.2 实验结果分析
3.2.1 学习表现预测首先对学习者的学习表现进行预测,将提出的知识情境感知的深度知识追踪模型与知识追踪基准模型进行比较.为了公平起见,实验没有引入使用辅助信息(如知识图谱[21]、试题文本[26])的模型.进行对比的具体的基准模型如下.
(1)BKT[2]:贝叶斯知识追踪模型,是传统知识追踪模型的代表,常作为知识追踪研究的基准模型.
(2)DKVMN[22]:基于深度学习的动态键值对记忆网络知识追踪,使用一个静态矩阵来存储知识概念,使用一个动态矩阵来存储和更新相应知识概念的掌握水平,以跟踪学习者不断变化的认知状态.
(3)DKT[4]:选用以试题编号为输入表征的深度知识追踪模型(DKT_Q)和以试题知识点编号为输入表征的深度知识追踪模型(DKT_KC).
(4)DIRT_4(Dynamic Cognitive Diagnosis Models with IRT)[27]:在深度项目反应理论模型的基础上整合知识点编号、难度和区分度的试题特征,对学生认知状态演变的顺序建模产生了积极影响.
(5)DNeuralCDM(Dynamic Cognitive Diagnosis Models with NeuralCDM)[27]:将认知诊断对教育先验的可解释性融入基于深度学习的知识追踪方法.
(6)AKT(Context-Aware Attentive Knowledge Tracing)[13]:使用注意力机制的知识追踪模型,通过指数衰减和上下文感知的相对距离来计算注意力权重,同时考虑试题之间的相似性,将历史交互信息和当前试题联系起来.
(7)SAINT(Separated Self-Attentive Neural Knowledge Tracing)[28]:基 于Transformer 的知识追踪模型,使用多层注意力机制,在编码器和解码器中分别对试题和作答记录进行编码.
首先在两个公开数据集上进行了实验,选择曲线下方面积(Area under Curve,AUC)和准确性(Accuracy,ACC)作为评价指标.实验结果如表2 所示,表中黑体字表示性能最优.由表可见,KCA-DKT 的性能优于基准模型,预测精度更好.和同为试题层级的融入教育先验的DIRT_4 对比,在ASSIST2009 数据集上,KCA-DKT 的AUC提 升5.93%,ACC提 升4.40%,在Algebra2006 数据集上则分别提升了7.97% 和2.49%,提升效果比较明显.

表2 各模型在学习者学习表现预测上的性能对比Table 2 Performance of each model on learner learning performance prediction
在Program 数据集上的对比实验结果如表3所示,表中黑体字表示性能更优.由表可见,KCADKT 模型同样具有更优的预测性能.

表3 KCA-DKT 和DIRT_4 模型在Program 数据集上的预测性能对比Table 3 Prediction performance of KCA -DKT and DIRT_4 on Program dataset
3.2.2 消融实验为了验证KCA-DKT 模型中各模块的有效性,在ASSIST2009 数据集上开展消融实验.KCA-DKT 和各变体模型(KCADKT_1 至KCA-DKT_5)的相关设置如表4 所示,表中“√”指对应模型中包含当前因素,“—”指对应模型不包含当前因素.

表4 KCA-DKT 及各变体模型的相关设置Table 4 The relevant settings of KCA_DKT and its variants
实验结果如图3 所示.由图可见,知识情境与猜测和失误因子等因素对模型的预测效果都有积极的影响.不考虑猜测和失误因子,仅考虑知识情境特征的KCA-DKT_1 仍有较好的性能,AUC和ACC略有下降;不考虑试题难度的KCADKT_2 与不考虑知识权重的KCA-DKT_3 相比,KCA-DKT_3 的AUC和ACC的下降更明显,证明知识情境的知识权重因素对模型性能的影响更大;不考虑知识情境的KCA-DKT_4 和不考虑知识情境特征与猜测和失误因子的KCA-DKT_5 两种模型预测能力的下降较明显,证明了知识情境特征在模型建模中的必要性.

图3 KCA-DKT 及其变体模型在消融实验中的预测性能Fig.3 Prediction performance of KCA-DKT and its variants in ablation experiments
3.2.3 不同序列长度下的预测实验为了评估KCA-DKT 是否能更好地建模学生的学习过程,对此进行了实验.一般地,完整的学习过程需要较长的学习序列,学习序列越短,学习过程越不完整.因此,设置了四个不同的最大序列长度进行实验,分别为20,50,100 和200.在ASSIST2009数据集上比较了KCA-DKT 和DIRT_4 在学习序列长度不同时对学生成绩的预测结果,图4 展示了序列长度不同时各模型的预测性能.由图可见,在学习序列长度不同时,KCA-DKT 的预测效果始终具有一定的优势.同时,随着学习序列的增长,KCA-DKT 的优势更加明显,即随着序列长度的增加,KCA-DKT 性能指标的上升幅度大于DIRT_4,表明KCA-DKT 受学习序列的影响较大,能更好地模拟学习者的长序列学习过程.在真实的学习环境中,获得的学习者的学习反馈越多,KCA-DKT 越能更好地掌握学习者的认知状态,给下游应用提供更准确的信息.
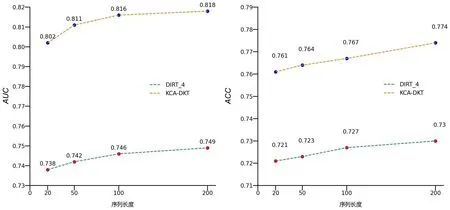
图4 不同学习序列长度的预测性能Fig.4 Prediction performance for different learned sequence lengths
3.2.4 案例分析1使用KCA-DKT 模型对ASSIST2009 数据集的一个具体学习者的知识追踪过程进行分析.该学习者在一段作答序列中对30个单知识概念试题作答,试题分别对应知识概念1、知识概念2、知识概念3,学习者对应的认知状态为知识状态1、知识状态2、知识状态3,实验结果如图5 所示.由图可见,试题的作答情况与对应的认知状态的变化基本一致.例如,学习者在知识状态1 对第1,3,5,6,7 题答错,则对应时刻的认知状态有明显的下降,证明了KCA-DKT 模型的有效性.

图5 ASSIST2009 数据集知识追踪过程示例Fig.5 The example of KT process on ASSIST2009 dataset
3.2.5 案例分析2表5 展示了KCA-DKT 模型对学习者学习表现的预测过程.对学习者理想作答的预测值为0.578,通过预定义的阈值(通常设置为0.5)来离散化对目标任务的预测结果后,学习表现的预测值为1,即学习者答对该道试题.但由于失误和猜测因子的存在,根据式(21)计算得到实际作答的预测值为0.489,离散后的结果为0,即学习者答错了该道试题,这与实际观测的结果一致.由此可见,在KCA-DKT 模型中利用认知诊断模型蕴含的教育理论特性引入猜测和失误因子,可以增强知识追踪预测的可解释性.

表5 学习者的学习表现预测过程Table 5 The prediction process of learners' learning performance
4 结论
针对目前知识追踪中没有考虑同一试题内的知识权重、试题表征过于简单的问题,本文提出一种知识情境感知的深度知识追踪模型,构建了知识情境嵌入模块来增强试题的表征.同时,从试题层级出发,结合知识权重和学习者的认知状态聚合计算来获得学习者的作答能力,最后引入认知诊断模型的猜测和失误因素,进一步提高模型的性能和可解释性.实验证明,本文提出的方法在学习者表现预测任务上的性能更优,同时具备了一定的可解释性.
未来将融合多模态数据表征试题信息以进一步增强构建知识情境表征,还将尝试将学习者的个性化特征与试题知识情境表征相结合,进一步提高模型的可解释性.
猜你喜欢
山西教育·招考(2021年5期)2021-11-30
法律方法(2021年4期)2021-03-16
当代陕西(2020年17期)2020-10-28
山西教育·招考(2019年6期)2019-09-10
学生导报·初中版(2019年5期)2019-09-10
中学课程辅导·高考版(2019年4期)2019-04-25
人大建设(2018年5期)2018-08-16
文教资料(2018年30期)2018-01-15
电信科学(2017年6期)2017-07-01
传播力研究(2017年5期)2017-03-28
