
基于优先度函数的概率不确定语言术语集双边匹配方法
2024-04-11 12:54白晓莉陈岩邓珍美
商丘师范学院学报 2024年3期
白晓莉,陈岩,2,邓珍美
(1.沈阳工业大学 理学院,辽宁 沈阳 110870;2.沈阳工业大学 管理学院,辽宁 沈阳 110870)
双边匹配研究可以追溯于Gale和Shapley[1]在关于婚姻匹配问题中的研究,研究中论证了双边稳定匹配的存在性以及最优性,并提出了著名的Gale-Shapley算法.自此之后,双边匹配问题的研究不断涌现于各个领域.例如,岗位与求职者匹配问题[2]、风险投资企业匹配问题[3]、医生与患者匹配问题[4]、物流服务供应方与需求方匹配问题[5]等.随着社会的发展,匹配问题背景愈加复杂,由于评价主体受专业知识限制,评价信息通常具有不确定性.不确定信息下的双边匹配问题是目前研究的热点,在不确定形式下,主体无法使用比较精确的数值进行评价,为了这一问题得到解决,学者们将直觉模糊、犹豫模糊[6]、区间犹豫模糊[8]、区间直觉模糊[9]、三角模糊[10]等方法引入双边匹配问题中,并应用于各个领域.但在模糊环境下进行评价,就意味着主体所提供的语言术语集的重要程度是一致的.实际并非如此,主体给出的语言术语集中的语言术语不一定是等概率的.在2016年,Pang[11]等学者们对犹豫模糊语言术语集中的每一个语言项都赋予了概率,定义了概率语言术语集(PLTS).因此,学者们开始对概率语言环境下双边匹配问题进行研究.Li等提出了一种在概率语言环境下,基于前景理论的属性权重未知的双边匹配方法.Li等[13]提出了基于概率语言偏好关系的双边匹配方法,其中给出了时间满意度的定义,并构建模型来处理概率语言偏好关系.Li等[14]学者提出了一种在概率语言术语集下,考虑最低可接受值的基于后悔理论双边匹配决策方法.汪新凡等针对概率犹豫模糊信息下准则具有期望水平的双边匹配问题,提出了一种考虑匹配主体心理行为的双边匹配方法.之后就有一些学者提出匹配主体可能更倾向用类似于[好,非常好]这种语言评价区间的形式来表达偏好信息,基于Xu[11]在2004年提出了不确定语言变量(ULV)的概念后,在2017年,由Lin等[17]提出了概率不确定语言术语集(PULTS)的概念.概率不确定语言术语集体现不确定语言术语集的概率特征,是概率语言术语集与不确定语言术语的扩展形式.但从目前来看,将概率不确定语言术语集应用于双边匹配问题中的研究鲜有涉足,并且已有研究大多以设立参照点获得主体相对优势,这会导致匹配主体评价信息的偏差,从而影响匹配结果.其次,为获得符合匹配主体偏好的匹配方案,匹配主体在匹配过程中的心理行为也应当充分考虑.
因此,本文对于概率不确定语言环境下的双边匹配问题进行了研究,并且考虑了主体的心理行为.首先,给出了概率不确定语言术语集区间型得分的定义,进而根据可能度公式计算概率不确定语言术语集间的可能度,比较概率不确定语言术语集的优劣程度;其次构造出优先度函数来反映匹配主体心理行为;然后,利用新的满意度公式构建满意度矩阵,建立双边匹配满意度最大化模型,通过求解模型,获得最优匹配方案;最后,进行算例分析,并与现有双边匹配方法进行比较,证明了所提出方法的优点.
1 基础知识
1.1 不确定语言变量
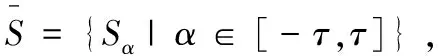
1.2 概率不确定语言术语集(PULTS)相关概念
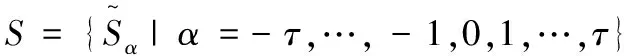
其中〈[Lk,Uk],pk〉表示不确定语言术语,且[Lk,Uk]的概率为pk,Lk和Uk是语言术语,满足Lk≤Uk,#S(p)是S(p)的基数.
Lin[17]等学者给出了概率不确定语言术语集标准化的方法:
(1)S(p)为任一概率不确定语言术语集,则已标准化的概率不确定语言术语集Sn(p)为
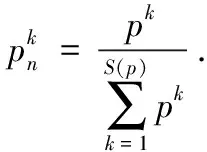
(2)如果#S1(p)<#S2(p),则给S1(p)增加具有概率为0的最小不确定语言变量#S2(p)-#S1(p)个,这样使得两个概率不确定语言术语集的基数相等.
定义3 设两个标准化概率不确定语言术语集为
那么它们的运算法则为
(3)λS(p)=∪〈[Lk,Uk],pk〉∈S(p){λpk[Lk,Uk]};
(4)(S(p))λ=∪〈[Lk,Uk],pk〉∈S(p){[Lk,Uk]λpk}.
其中λ≥0.
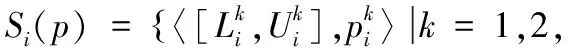
=
为概率不确定语言术语集平均算子(PULA).
1.3 双边匹配
设双边匹配主体集合分别为A={A1,A2,…,Am},B={B1,B2,…,Bn},其中,Ai表示A中的第i个主体,i∈M,M={1,2,…,m}.Bj表示B中的第j个主体j∈N,N={1,2,…,n}.一般地,m≥n.
定义5 设一一映射μ:A∪B→A∪B,若∀Ai∈A,∀Bj∈B,满足:
(1)μ(Ai)∈B;
(2)μ(Bj)∈A∪{Bj};
(3)μ(Ai)=Bj当且仅当μ(Bj)=Ai.
则称μ为双边匹配.其中μ(Ai)=Bj或μ(Bj)=Ai,表示Ai与Bj在μ中匹配,记为(Ai,Bj);μ(Bj)=Bj表示Bj在μ中未匹配,记为(Bj,Bj).
2 优先度函数
2.1 可能度

定义6 对于任意的概率不确定语言术语集S(p)={〈[Lk,Uk],pk〉|pk≥0,k=1,2,…,#S(p)},称
为概率不确定语言术语集的区间型得分.
定义7 概率不确定语言术语集间的可能度定义为:
(1)
①若0.5<ρ(S1(p1)≥S2(p2))≤1时,则S1(p1)优于S2(p2),记为S1(p1)≻S2(p2);②若ρ(S1(p1)≥S2(p2))=0.5时,则S1(p1)和S2(p2)无差异,记为S1(p1)~S2(p2);③若0≤ρ(S1(p1)≥S2(p2))<0.5时,则S1(p1)劣于S2(p2),记为S1(p1)S2(p2).
显然,通过此公式,不仅能够反映出概率不确定语言术语集间“期望”的差异,还可以反映它们之间“方差”的差异;其次,此公式无需借助像 Lin等学者提出的双层比较的方式,就可以进行概率不确定语言术语集间的优劣比较,并能度量出两个概率不确定语言术语集间的优劣程度.
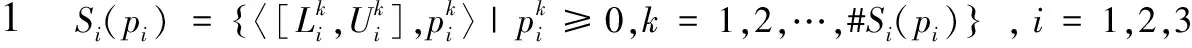
(1)有界性:0≤ρ(S1(p1)≥S2(p2))≤1;
(2)互补性:ρ(S1(p1)≥S2(p2))+ρ(S2(p2)≥S1(p1))=1;
(3)自反性:当S1(p1)=S2(p2)时,ρ(S1(p1)≥S2(p2))=0.5;
(4)传递性:ρ(S1(p1)≥S2(p2))≥0.5,ρ(S2(p2)≥S3(p3))≥0.5,则ρ(S1(p1)≥S3(p3))≥0.5.
证明
(1)由定义7可知,可能度满足0≤ρ(S1(p1)≥S2(p2))≤1.
(2)分两种情况讨论,第一种情况,当SL1≥SU2时,ρ(S1(p1)≥S2(p2))=1,而ρ(S2(p2)≥S1(p1))=0,满足ρ(S1(p1)≥S2(p2))+ρ(S2(p2)≥S1(p1))=1;
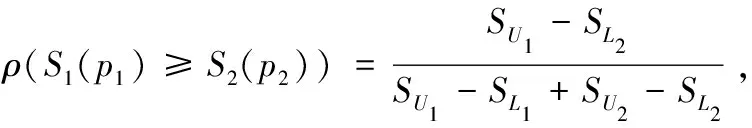
(3)根据公式(1),当S1(p1)=S2(p2)时,SL1=SL2,SU1=SU2,因此,ρ(S1(p1)≥S2(p2))=0.5.
(4)ρ(S1(p1)≥S2(p2))≥0.5,ρ(S2(p2)≥S3(p3))≥0.5时,
可以推导出SU1-SL2≥SU2-SL1,SU2-SL3≥SU3-SL2,接着推导出,SU1-SL3≥SU3-SL1,再由公式
因此,ρ(S1(p1)≥S3(p3))≥0.5.
2.2 优先度
定义8 设任意两个已标准化的概率不确定语言术语集为

(2)
其中0≤ρ≤1.
进一步说明,当ρ∈[0,0.5)时,S1(p1)S2(p2),此时ρ*<0;当ρ=0.5时,S1(p1)和S2(p2)无差异,ρ*=0;
当ρ∈(0.5,1]时,S1(p1)≻S2(p2),此时ρ*>0.
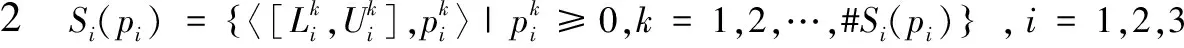
(1)-0.5<ρ*(S1(p1)≥S2(p2))<0.5;
(2)互补性:ρ*(S1(p1)≥S2(p2))+ρ*(S2(p2)≥S1(p1))=0;
(3)自反性:当S1(p1)=S2(p2)时,ρ*(S1(p1)≥S2(p2))=0;
(4)传递性:ρ*(S1(p1)≥S2(p2))≥0,ρ*(S2(p2)≥S3(p3))≥0,则ρ*(S1(p1)≥S3(p3))≥0.
由定理1及证明和公式(2),可证明优先度函数具有以上性质.
2.3 距离测度
为了避免匹配主体评价信息中偏倚数据的影响,根据区间型得分,定义了两个概率不确定语言术语集间的距离测度.
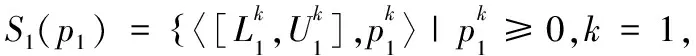
(3)
定理3 给定概率不确定语言术语集S1(p1),S2(p2),S3(p3),则式(3)满足:
(1)d(S1(p1),S2(p2))≥0;
(2)d(S1(p1),S2(p2))=d(S2(p2),S1(p1));
(3)d(S1(p1),S2(p2))+d(S2(p2),S3(p3))≥d(S1(p1),S3(p3)).
注:d(S1(p1),S2(p2))=0当且仅当S1(p1)与S2(p2)相等.
3 基于优先度函数的双边匹配模型与方法
3.1 双边匹配问题描述
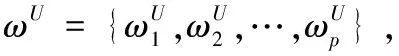
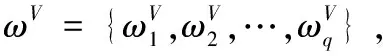
3.2 满意度计算
双边匹配的目标是使得双边匹配主体满意度最大,由式(2)、式(3)概率不确定语言术语集的优先度函数以及距离测度,在此定义双边匹配主体的满意度.
定义10 设SdAi→Bj是在属性Up下,匹配主体Ai对匹配主体Bj的满意度,其计算公式为
(4)
定义11 设SdBj→Ai是在属性Vq下,匹配主体Bj对匹配主体Ai的满意度,其计算公式为
(5)
那么,匹配主体Ai对于Bj的综合满意度以及匹配主体Bj对于Ai的综合满意度分别为
(6)
(7)
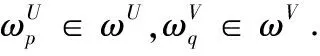
3.3 双边匹配模型
基于以上匹配双方满意度矩阵的计算,建立了匹配双方满意度最大化目标双边匹配模型P1如下:
(8)
(9)
(10)
(11)
其中,xij为0-1变量,xij等于1时,说明Ai与Bj匹配,xij等于0时,说明Ai与Bj不匹配.式(8)是表示匹配主体A的最大化满意度,式(9)是表示匹配主体B的最大化满意度,式(10)表示任一匹配主体A只能与一主体B匹配或不匹配,式(11)表示任一匹配主体B与一匹配主体A匹配.
由于匹配双方的目标函数是等级的,因此,通过线性加权法可将多目标模型P1转化为单目标模型P2,分别加权α和β(0≤α,β≤1,α+β=1).则P2为:
3.4 双边匹配方法步骤
基于概率不确定语言术语集下考虑心理行为的双边匹配问题,提出了优先度函数和距离测度,用于构造满意度矩阵,进而建立双边匹配模型,具体步骤如下:
Step 2 对评价信息进行标准化处理,并集结属性准则下的评价信息.
Step 3 将已标准化的评价信息,根据定义6和式(1)-(5)求得SdAi→Bj和SdBj→Ai.
Step 4 利用式(6)、(7)得到满意度aij和bij,进而构造满意度矩阵A=[aij]m×n和B=[bij]m×n.
Step 5 构建多目标模型P1,并将其转化为单目标模型P2.
Step 6 用Kuhn-Munkras算法求解模型P2,得到最优匹配方案.
4 算例分析
4.1 问题描述
某工业园有3家新进企业需要实施仓储管理系统(WMS),通过服务中介机构投放广告等相关信息,有4家软件供应商有合作意向,记为Ai(i=1,2,3,4),这3家软件需求企业记为Bj(j=1,2,3),软件供应商Ai对软件需求企业Bj评价的参考属性为U1(系统实现的收益)、U2(企业规模)、U3(发展前景),加权向量为
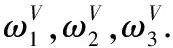
S={s-3:非常差,s-2:较差,s-1:差,s0:中等,s1:好,s2:很好,s3:非常好}.
4.2 求解过程
Step 1获得评价信息.

表1 在属性U1下的评价信息矩阵

表2 在属性U2下的评价信息矩阵

表3 在属性U3下的评价信息矩阵

表4 在属性V1下的评价信息矩阵

表5 在属性V2下的评价信息矩阵

表6 在属性V3下的评价信息矩阵
Step 2根据式(1)-(5)分别求得满意度SdAi→Bj和SdBj→Ai,如下表7、8所示:

表7 Ai对Bj满意度矩阵

表8 Bj对Ai满意度矩阵
Step 3 利用式(6)、(7)获得满意度aij和bij,进而构造满意度矩阵A=[aij]4×3和B=[bij]4×3.
Step 4 构建多目标模型P1,令α=β=0.5,将多目标模型P1转化为模型P2.
Step 5 将综合满意度作为二分图匹配中的权值,用Kuhn-Munkras算法求解模型P2,获得双边匹配矩阵为
所以最优匹配方案为{(B1,A2),(B2,A3),(B3,A4)}.
4.3 比较分析
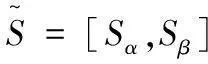

表9 不同匹配方法的对比
表9显示,这4种不同的匹配方法所对应的匹配方案存在差异,进一步分析存在差异的原因:
文献[12]、文献[19]中均应用前景理论来考虑匹配主体心理行为,但前景理论需要考虑双边匹配主体的损失规避系数、风险厌恶系数和风险偏好系数,参数较多,计算较冗杂,本文的优先度不需要考虑参数的设置,计算较简洁;文献[14]中通过概率语言术语集期望值与匹配主体评价值的方式来获得满意度会导致综合满意度偏高或偏低,从而影响匹配结果.
文献[14]的双边匹配方案与本文的方案不完全一致,造成这种差异的主要原因:一方面在于文献[14]构建基于期望值的满意度函数,建立了基于后悔理论的双边匹配模型,这样应用期望值会导致评价信息的失真,后悔理论也仅反映了匹配主体的后悔心理;另一方面在于文献[14]考虑了最低可接受度,但最低可接受度是假设的虚拟值,选取不同可能会对匹配结果有影响.本文应用优先度与距离测量来获得满意度,可以避免信息的失真,从而确保匹配结果更合理,更准确.并且参照点设置为评价信息的综合平均值而不是虚拟值,这样不但可以集中于原始评价信息,而且使计算更简化,本文中提出的优先度函数不同于后悔理论,它能更灵活的反映匹配主体的趋优性、规避劣性的心理行为.
5 结 论
针对概率不确定语言环境下的双边匹配问题,考虑双边主体趋优性的心理行为特征,提出了一种基于优先度函数的双边匹配方法.(1)定义概率不确定语言术语集区间型得分,给出可能度公式,以此把定性信息转化为定量分析,使得匹配结果更符合匹配双方主体的预期.(2)定义的优先度函数和距离测度为处理概率不确定语言环境下的双边匹配问题提供了一种有力工具,有效避免了目前研究中直接应用期望值或评分值的方式来获得满意度所导致的信息失真.(3)定义的优先度函数可以反映主体趋优性和规避劣性的心理行为且不需要考虑参数的设置,计算较简洁.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
中国资源综合利用(2017年4期)2018-01-22
浙江大学学报(工学版)(2016年9期)2016-06-05
焊接(2015年5期)2015-07-18
天津冶金(2014年4期)2014-02-28
中国科技术语(2012年3期)2012-03-20
中国科技术语(2012年3期)2012-03-20
