
基于语言计量特征的文学翻译质量评估模型的构建
2016-08-05 04:01祁玉玲蒋跃西安交通大学外国语学院陕西西安710049
西安电子科技大学学报(社会科学版) 2016年1期
祁玉玲,蒋跃(西安交通大学 外国语学院,陕西 西安 710049)
■语言学
基于语言计量特征的文学翻译质量评估模型的构建
祁玉玲,蒋跃
(西安交通大学外国语学院,陕西西安710049)
本研究结合语料库翻译学与计量语言学的理论和方法,依托国内外各种大型语料库,通过采集翻译文本的各种语言计量特征的参照数据,对其进行加工、整理和测算,建立起翻译质量评估的参照模型,以期对翻译产品的质量做到量化和客观化评估,并借助软件,实现评估过程的标准化和自动化,最后选取了五个各有20万字的汉语译本对该评估模型进行测试,并对评测的结果进行解释。结果表明,此模型对译文的质量评估有一定的参考作用。
语料库翻译学;计量语言学;翻译质量评估;量化
一、引言
翻译质量评估是译学一项新兴的研究内容,也是翻译研究不可或缺的一部分[1]。对于翻译的质量评估,目前有一些较为出名的评估模式,例如,Reiss、House 、Williams和Nord的翻译功能理论为主导的文本分析模式等翻译质量评估理论和模式[2-5]。这些模式的基本思想都是通过设立的一些参数(文本类型,语言风格等),对比译文和原文,其参数的设定全面而又具体,但也有一些缺憾,这些模式或参数因为始终需借助人来评判,而无法量化,在评估结果的科学性、客观性、可靠性以及推广性上有些问题。
与人工评估相对应的是机器评估,为人们所熟知的有BLEU(Bilingual Evaluation Understudy)和NIST(National Institute of Standards and Technology)等评测方法“都是从文本的N元词语出发,比对测试文本和参照文本之间的N元词语的相似程度,计算出被测文本和参考译文之间的距离”[6]184。这两个评测方法虽做到了客观和量化,但因只局限在词汇层面,没有从句子、段落和篇章层面进行译文的评估,因而评测的范围不够全面。
近年来,随着语料库技术的发展和计量语言学方法的出现,用语言计量特征去统计译文的语言计量特征、辨别译者、评估译者语言风格已很普遍。作家在语言表达中会有不同的言语特征,表现在数量上就是统计特征上的差异。同理,不同的译文也会在数量上有语言计量特征上的差异。蒋跃通过计量语言学方法,对人工译本和机器译本的13个语言结构计量特征进行了考察,从而对人工译本和在线机译译本的词法和句法层面的各种语言计量特征以及总体的翻译做出评比,并指出计量语言学的计量方法可用于各译本间的对比[7]98-102。
译文由于可作为一种独立的文体,是介于原语和目的语之间的第三语体,可以在一定程度上反映出自然语言的语言计量特征。而众多译本构成的语料库,如浙江大学汉语译文语料库(ZCTC),汉英对应语料库(CEPC) 和当代汉语翻译小说语料库(CCTFC)等大型语料库,描写翻译学家和语料库翻译学家已经发现,翻译语言具有一定的共性。而这些共性都是依托于其所建立的语料库中的语言计量特征提取和测算出来的,体现在各种计量特征上。
因此,我们假设,这些基于大型语料库的语言计量特征在一定程度上准确反映了翻译语言的共性和各种基本特征。既然如此,或许这些语言计量特征可以作为衡量测评一个译本翻译质量的参照标准。有鉴于此,本研究结合语料库翻译学和计量语言学的理论和方法,从中提取并确立一些语言计量特征作为翻译质量评估标准的参数。然后基于各类国内大型双语语料库,采集大量的翻译语言的计量特征的数据。基于这些数据,建立了一个基于语言计量特征的翻译质量评估模型,用以对文学译文翻译质量做出客观的评估,从而避免人为评判的主观性,并且借助软件,实现评估过程的自动化、评估结果的科学性和可靠性。
二、研究设计
(一)模型的构建步骤

图1:翻译质量评估模型的构建步骤
(二)模型的参数
黄伟、刘海涛提出的用于文本聚类的汉语计量特征,其中包括词长、句长、型例比、副词比例、名词比例、代词比例、助词比例、标点符号比例、陈述句比例(句号比例)、疑问句比例(问号比例)、感叹句比例等11类[8]。为了多维度、更全面地评估,在以上11个语言计量特征的基础上,我们进行了拓展,建立了23个语言计量特征构成的翻译质量评估指标体系。
(1)标准类符/形符比(STTR)
标准类符形符比,可以用来衡量词汇的差异度[9]。类符指的是语料库中不同的词语,形符是指所有词形。Mona Baker指出,如果比值低,就意味着文本的词汇量较小,词汇变化小,如果比值大,则说明译者用的词汇量较大[10]。但是否STTR的值越高越好,并不尽然。STTR统计的类符包括是实义词和功能词,过度修饰的篇章由于功能词的增加可能会提高STTR值,但并不意味着信息量的增加[6]84。
(2)词汇密度
词汇密度高说明译文中实义词比重大、信息量大、译文简练,使用的词汇少但表达更准确、完整;相反词汇密度低说明功能词比重偏大,这样的译文结构会更加清晰易懂,但不免繁冗[11]113。显而易见,关于词汇密度,应有一个比较合理的区间,词汇密度过高或过低,都不能成为一个好的译文。词汇密度有两种算法,一种是实义词与功能词之比,一种是实义词与总词数之比。鉴于多数研究都采用了第二种算法,本文采用实义词与总词数之比。
(3)平均句长
句长值的研究是语料库语言学、计量语言学和统计风格学(stylometry)以及作者身份判别研究中具有相当应用意义的指标[7]100。句子的长短与其所含的信息量有一定的关系。“在翻译文本中,句子的长度关系到原文信息是否全部传达,是否有补充信息或怎样实现信息的传达”[11]114。
同时,译文的平均句长也是译者风格和译本语言特征的一般标记[12]。不同译者在句法层面的操作,既是翻译目的和译者主体性的体现,也是其语言风格特征的展示。平均句长可以反映出译文的扩增与否和可读性的强弱情况。如果句长过长,则说明译文扩增现象明显,可读性较差;如果句长较短,则说明译文的可读性较强。
(4)平均词长
“单词长度一直是文本研究中被忽略的地方,而单词长度可以反映出译者的用词习惯和风格”[11]113。1932年,Zipf在研究英文单词出现的频率时发现,如果把单词出现的频率按由大到小的顺序排列,则每个单词出现的频率与它的名次的常数次幂存在简单的反比关系,这种分布就称为“Zipf定律”。该定律表明,在自然语言的词语当中,只有极少数的词被经常使用,而绝大多数词很少被使用。实际上,包括汉语在内的许多语言都有这种特点。虽然英文和汉语计量词的长短的单位不一样,但有一个共性是词越长,承载的词义越少[13]11。而平均词长也可以用来测量语篇难度,反映语篇的词汇特征。
(5)各类词比例
各类词涵盖了名词、动词、形容词、副词、代词、数词、量词、连词、介词、助词、语气词等。作为实义词,名词、动词、形容词、副词的比例广被研究。对于功能词的研究,肖中华通过研究发现,翻译汉语具有超用代词、介词与连词等功能词的趋势[14]86。而超用的范围是多少,必须有一个界定。而语气词的研究,是译文对原文情感识别和处理再现的重要指标。“就英语小说汉译而言,添加语气词可以彰显人物思想的连贯性,使译文逻辑更加清晰,语言表达更符合汉语习惯”[15]。译文有自己的独立特征,所以,通过翻译文本建立起来的翻译标准对评价译文有重要的意义。
(6)标点符号比例
现代汉语成体系的标点符号系统出现在二十世纪以后,“作为文字语言的辅助,标点符号具有重要的语篇衔接功能”[16]26。正确运用标点符号可以帮助读者分清句子结构,辨明语气,准确了解文意[17]。肖中华通过对标点符号的研究,发现翻译汉语和原创汉语在标点符号的使用上明显存在区别,翻译汉语有明显的受英语原文影响的倾向[14]93。这也是翻译汉语独立于英语和汉语之外,作为“第三语体”存在的一个例证。
(7)习语比例
习语,对应英文的idiom,广义的习语包括惯用语,熟语,成语,格言和歇后语。“习语是汉语词汇的重要组成部分,其特点是结构比较复杂,意义具有整体性”[18]。在评价翻译质量的活动中,习语密度的使用频率和密度往往也应该作为一个重要的衡量指标[7]101。黄立波指出,习语的密集度或分布特征能表明一个译者对译入语习语的掌握的熟练程度,也能表明其语言和词汇的丰富度和变化度,还可以表现译者对原文的词语演绎归纳的能力[19]。
(8)词表前30项高频词比例
对高频词的研究大多只关注前10位的高频词的词性及其与原文词语的对应情况。胡显耀则把研究范围拓展到高频词的前30位,通过研究指出,如果前30位高频词所占总词数的比例过高,说明翻译小说大量使用高频词,词汇简化明显[20]。这是由于译者有意或无意地重复使用较少数量的常用词语,这虽然会使文本的难度降低,可接受性提高,但比例过高,会使文本的独特性减少。
(三) 模型中参数的数值来源
Laviosa指出,与汉语母语相比,汉语译文呈现出一种“整齐化”或“集中化”趋势与特征,即“汉语译文具有相对较高的同质特征”,亦即“共性”[21]。鉴于翻译汉语,既不能根据原语言语库,也无法按照目标语言语料库来加以解释,所以,本研究的目标锁定在汉语翻译文本,对其各语言计量特征进行搜集,整理,以建立从第三语体角度的翻译质量评估模型。
首先是在中国知网上检索出全部的英译汉译本的学术论文。然后根据这些论文的评价和评估,进行样本译本的筛选。最终确定了11部文学英语作品的34个汉语译本为译本样本,其中包括《尤利西斯》两个译本、《飘》的三个译本、《简爱》的三译本、《老人与海》的四个译本、《爱丽丝梦游仙境》的三个译本、《哈姆雷特》的三个译本、《温莎的风流娘们》的三个译本、《苔丝》的三个译本、《马丁伊登》的五个译本、《鲁滨逊漂流记》的两个译本、《查泰莱夫人的情人》的三个译本。
除了上述数据,我们也使用了三个大型语料库的数据,其中包括北京外国语大学的通用汉英对应语料库(CEPC),浙江大学汉语译文语料库(ZCTC),当代汉语翻译小说语料库(CCTFC)。
文献[13]中对该协议的安全性进行了详细的证明。在半诚实模型下,该协议是(m-1)-隐私[14]的,即前m-1个参与方共谋,也无法推测出第m个参与方的有效数据。
数据的来源范围一经确定,我们就对各个参数的数据进行提取和整理。整理过程中发现,有些参数的研究较为普遍,例如,标准类符形符比,平均句长,词汇密度,有些参数的研究甚少,但也有数据可寻,如逗号比例、分号比例和顿号比例等。最后根据搜集的每个语言计量特征的数据,进行大小顺序排列,最小的数值和最大的数值组成了此语言计量特征的数值区间(前30项高频词例外)。各数值区间如下图所示。

表1:基于语言计量特征的23个评估参数
三、翻译质量评估模型的建立与检验
(一) 建立模型
本翻译质量评估模型是为了检验翻译文本的23个语言计量特征是否能符合所建的模型的标准,符合的程度有多大。模型的公式如下:

每个测试文本的得分是23个语言计量特征差值的相加,即Ci表示的是每一个语言计量特征距标准的差值,0.0438表示的是每一个语言计量特征占模型的权重,di表示的是每个计量特征的中间值。差值的计算分了三类情况,符合标准,则差值是0,大于每个参数区间的最大值和小于区间的最小值则分别是不同的算法。
基于上述的评估公式,同时,出于简便操作过程和便于此评估模型推广性的考量,我们进行了计算机编程,编程基于的思想是自动计算每个计量特征的差值和最后的总差值。每个计量特征的计算过程如图2所示。
基于以上的想法,同时,出于简便操作过程和便于此评估模型推广性的考量,我们进行了计算机编程①,编程语言采用C#②,软件用的是Visual Studio③,使评估的操作过程实现自动化。程序语言,限于篇幅,在这里就不一一列出。最终的操作界面如图3所示,评测者只需将被测试的译文数据输入第三列空白框,第四列就会显示符合标准与否,以及差值,最后,程序输出总差值。
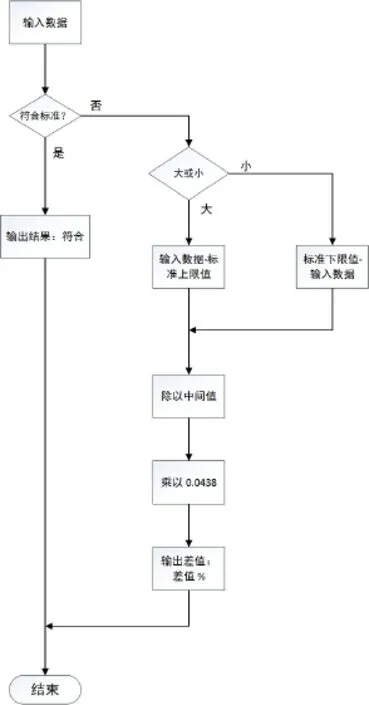
图2:每个参数的计算流程

图3:文学翻译质量评估模型界面
(二) 模型的检验
为了对本模型进行检测,我们选取了《傲慢与偏见》的五个译本作为测试样本。分别是王科一,孙致礼,张经浩和张玲的共四个人工译本,另一个是百度在线译本。
首先需要明确指出的是各个语言计量特征的计算方法。
(1)标准类型比(STTR)可以通过Wordsmith工具直接计算得出。
(2)各词类的比例=各词类的数量/总词数
(3)词汇密度=名词、动词、形容词和副词的总数/总词数
(4)词长=总词数/总字数
(5)句长=总字数/总句数
(6)各标点符号比例=各标点数量/ 总字数
(7)前30个高频词比例=前30个高频词的数量/总词数
根据已确定的23个语言计量特征及其算法,对五个译本的各个特征进行了数据提取及运算。
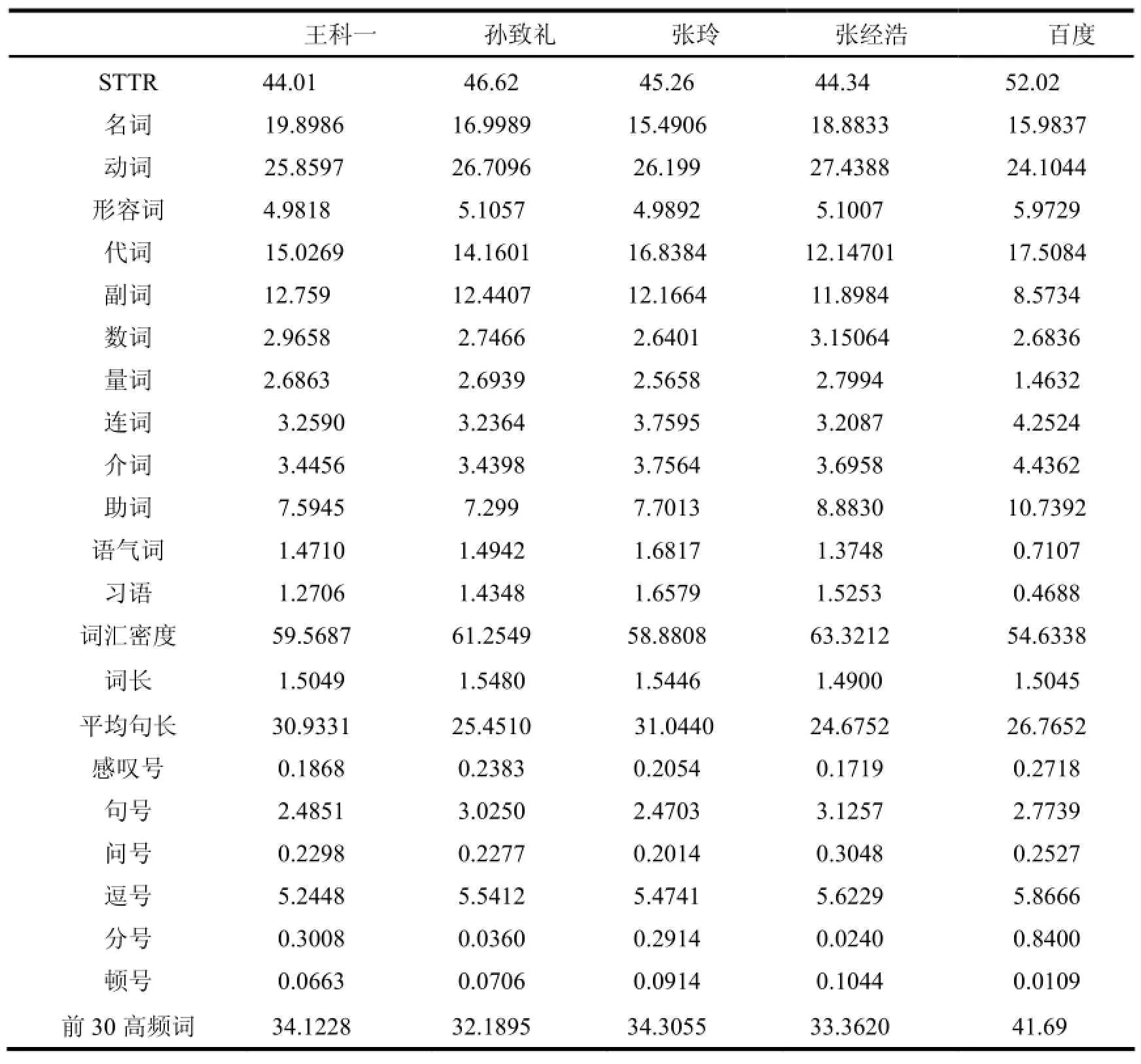
表2:五个译本的23个语言计量特征数据
接下来,分别对五个译本进行检验。最终的评测结果如表3所示。
从五个译本的检验结果来看,人工译本符合标准的程度都在80%以上,其中,张经浩的最高,达到了93.07%,而机器在线译本符合标准的程度则相对较低。从模型的单个参数的符合情况来看,有些参数的符合情况较为一致,像 STTR,名词比例,形容词比例,平均词长,感叹号比例,被测的五个译本全部符合,我们可以判定这五个语言计量特征的数值较为稳定,在不同译文之间有较高的一致性。不符合的情况下,不同译文之间也有相似,有些参数是较为一致的高于参数标准,有些则是较为一致的低于参数标准,可能是受英语原文的影响。符合的项数从张经浩最高13项符合到最低的王科一的8项符合,相较于百度在线的10项符合还要低,但由于王科一不符合的程度相较于百度的要小,所以最终符合质量评估模型的要高。由评测结果可看出,此质量评估模型可以对译文进行可靠的评测。

表3:五个译本的翻译质量评估结果
四、结语
本研究的统计分析结果表明,本研究所建立起来的文学作品翻译质量评估模型可以对文学翻译作品的质量从语言计量特征的角度做出评判,借助软件,可以实现操作的自动化和简便化。此评估模型涉及到语言结构多个维度的评估,从词法、句法到整个语篇层面,可以为文学翻译译文的评估从提供较好好的参考。
当然,本评估模型有一个制约因素,这便是需要对评审的译作进行评估前的分词标注及对语料的人工清洗,这个工作量稍嫌繁重。正如杨志红所说,未来评估模式应注重译文整体效果评估与微观层面评估的结合,需要对多种评估模式进行综合运用[22]。翻译质量评估还有很多工作要做,还有很长的路要走。
[注释]
① 软件编程得到了机械工程学院杜志国同学的帮助,在此表示感谢。
② 由C和C++衍生出来的面向对象的编程语言
③ Visual Studio 是微软公司推出的,目前最流行的Windows平台应用程序开发环境,可以用来创建 Windows 平台下的 Windows 应用程序和网络应用程序,也可以用来创建网络服务、智能设备应用程序和 Office 插件。
[1] 何三宁.翻译质量评估在我国译学中的定位[J].湖北大学学报(哲学社会科学版),2008(6):120-124.
[2] REISS K.Translation Criticism-the Potentials and Limitations: Categories and Criteria for Translation Quality Assessment [M].Manchester:St. Jerome Publishing,2000: 9-106.
[3] HOUSE J.A Model for Translation Quality Assessment[M].TÜbigen:Gunter Narr,1981:1-344.
[4] WILLIAMS M.Translation Quality Assessment:An Argumentation-Centered Approach[M].Ottawa:University of Ottawa Press,2004:3-19.
[5] NORD CHRISTIANE.Text analysis in translator training[C]//CAY DOLLERUP,ANNE LODDEGAARD.Teaching Translation and Interpreting.Amsterdam & Philadelphia:Benjamins,1994:39-48.
[6] 王克非.语料库翻译学探索[M].上海:上海交通大学出版社,2012.
[7] 蒋跃.人工译本与机器在线译本的语言计量特征对比-以5届韩素音翻译竞赛英译汉人工译本和在线译本为例[J].外语教学,2014(5).
[8] 黄伟,刘海涛.汉语语体的计量特征在文本聚类中的应用[J].计算机工程与应用,2009,45: 25-33.
[9] SCOTT M.The Wordsmith Tools(v.4.0)[CP].Oxford: Oxford University Press,2004.
[10] BAKER M. Towards a methodology for investigating the style of a literary translator[J].Target International Journal of Translation Studies,2000(12):241-266.
[11] 霍跃红.基于语料库的译者文体比较研究[J].大连理工大学学报(社会科学版),2010,31(2):111-115.
[12] OLOHAN M.Introducing Corpora in Translation Studies[M].London,New York:Routledge,2004:90-167.
[13] ZIPF G K.The Psycho-Biology of Language:An Introduction to Dynamic Philology[M].London:G. Routledge & Sons Ltd.,1936:46.
[14] 肖中华.英汉翻译中的汉语译文语料库研究[M].上海:上海交通大学出版社,2012.
[15] 刘泽权,陈冬蕾.英语小说汉译显化实证研究——以《查泰莱夫人的情人》三个中译本为例[J].外语与外语教学,2010(4):8-13.
[16] 梁丽,王舟.标点符号的语篇衔接功能与英汉翻译中的信息处理[J].中国翻译,2001,22(4):26-29.
[17] 语言文字规范手册(最新版)[M].北京:商务印书馆国际有限公司,2014:243-374.
[18] 佘秋颖.描写翻译学视角下的《马丁伊登》翻译研究-以六个译本翻译为例[J].牡丹江教育学院学报,2011(3):74-76.
[19] 黄立波.翻译研究的文体学视角探索[J].外语教学,2009(5):82-85.
[20] 胡显耀.当代汉语翻译小说规范的语料库研究[D].上海:华东师范大学,2006.
[21] LAVIOSA S.Corpus-based Translation Studies:Theory,Findings,Applications[M].Amsterdam:Rodopi,2002:72.
[22] 杨志红.翻译质量量化评估:模式、趋势与启示[J].外语研究,2012(6):65-69.
本文推荐专家:
徐玉臣,长安大学外国语学院,教授,研究方向:语篇中语言评价系统。
魏在江,广东外语外贸大学英文学院,副教授,研究方向:英汉对比与翻译。
Establishment of a Model for Quality Assessment of Translated Literary Works based on Quantitative Linguistic Characteristics and Corpora
QI YULING,JIANG YUE
(School of Foreign Studies, Xi'an Jiaotong University, Xi'an, 710049, China)
Using the corpus-based translation study, quantitative linguistics method, and various corpora,this study establishes a translation quality assessment model by collecting, processing, and analyzing the data of stylistic characteristics with the purpose of assessing the quality of translation quantitatively and objectively. With the aid of software, standardization and automation of the evaluation process is achieved. To test the quality model, five translated texts each with 20,0000 words are chosen. The results show that the translation quality assessment model has referential value to the quality assessment of the translated texts.
Corpus-based Translation Studies; Quantitative Linguistics; Translation Quality Assessment ;Quantitatively
H059
A
1008-472X(2016)01-0084-09
2015-11-07
教育部社科规划基金项目“在线机译与人工翻译的语言计量特征对比”(项目编号:15YJA740016)
祁玉玲(1991-),女,山东临沂人,西安交通大学外国语学院硕士,研究方向:医学英语、模糊语言与语料库翻译学;蒋跃(1958-),男,四川成都人,西安交通大学教授,研究方向:计量语言学与语料库翻译学。
猜你喜欢
中国神经再生研究(英文版)(2022年2期)2022-08-08
天津外国语大学学报(2020年1期)2020-03-25
西夏研究(2019年1期)2019-03-12
小天使·二年级语数英综合(2017年12期)2017-12-05
西夏学(2017年1期)2017-10-24
小学生学习指导(低年级)(2017年6期)2017-02-16
语言与翻译(2015年4期)2015-07-18
外语教学理论与实践(2014年4期)2014-06-13
小学生时代·大嘴英语(2006年1期)2006-06-06
军事历史(1993年5期)1993-08-21
