
从全文检索到语言计量和语言智能*
——语料库研究应用的三个层次及资源
2024-01-24 06:27张艺璇冯敏萱
外语研究 2024年1期
李 斌 张艺璇 冯敏萱
(南京师范大学文学院,江苏南京 210097)
0.引言
语料库是语言学研究的重要基础资源。纵观语料库发展历史,计算机技术的发展推动着语料库建设和研究不断深入。语料库的兴起得益于计算机技术的进步,由纸质文本转换为电子文本,给语言的储存和计算带来了极大便利。语言研究需要语言材料为研究对象,在电子语料库出现以前,卡片式的摘录和统计已经是语言研究的基本方法之一,可以看做是现代语料库方法的雏形。而大规模电子语料库的出现,为语言研究开辟了更广阔的研究空间。随着研究需求的扩大,语料库研究呈现精细化、多样化的特点,语料库的类别也愈加丰富多样。
截至目前,语料库已经历了三个发展阶段。20 世纪60 年代,第一代电子语料库的典型代表为BROWN 语料库,除了标注原始语料的元数据,如作者、写作时间、体裁等,一般对语料内容几乎不作标注,规模大多为百万词次。20 世纪80 年代,第二代电子语料库规模开始扩大,常常达到千万词次,甚至上亿词次,典型代表为COBUILD 语料库。这一阶段对于语料的标注也更为深入。20 世纪90 年代,由于语料库的简单标注已不能满足语言研究的需要,且面对语言智能中机器学习算法对高质量语料的迫切需求,第三代电子语料库以宾州树库为代表,开始逐渐探索句法、语义和篇章等语言信息的深度标注。伴随计算机算力的不断提高,标注内容的不断深入极大地丰富了语料库的规模、深度和模态,推动语料库的构建与应用研究不断创新。
学界从诸多不同角度对语料库进行了分类:从语料选取时间角度,可分为历时语料库与共时语料库,如“CCL 语料库”即为典型的历时语料库;从语料库的内容角度,可分为平衡语料库与自然随机语料库,如“国家语委现代汉语通用平衡语料库”为平衡语料库;从语料用途角度,可分为通用语料库与专用语料库,如牛津大学出版社等机构联合开发的“BNC 语料库”为通用语料库;从语种丰富度角度,可分为单语语料库与多语语料库,“CCL 语料库”包含了部分汉英双语语料库;从语言产出者身份角度,可分为本族语者语料库与学习者语料库,如北京语言大学构建的“HSK 动态作文语料库”即为学习者语料库;从标注层次角度,可分为未作任何标注的生语料库和经过标注的熟语料库,后者包括分词语料库、词性标注语料库、树库、命题库和篇章树库等。另外,随着传播媒介的日渐多样化,语言研究已经逐渐超出了文本形式,开始与音频、视频等多种模态相融合,建设了大批多模态语料库,如“现场即席话语多模态语料库”(顾曰国2013)。
通过对语料库类别的简要梳理,可以看出学界对语料库的划分大多从语料库的语言材料属性和标注层次的角度考虑,较少从语料库构建的目的和功用来讨论。一般来说,语料库的服务对象是普通用户和专业学者。普通用户以文本阅读和简单查阅为主,语言研究者则从语料库中查检用例,使用个案分析或计量分析方法,总结语言规律,或者为了研究特定的语言现象,进而建设大规模带标注的语料库。而在人工智能的研究中,主要采用机器学习方法来处理语言,以计算建模的方式构建特定语言任务的数学模型,以大量的训练语料来优化模型的参数,从而实现自动标注和语言分析。面向机器学习的语料库建设早已成为计算语言学界的主要领域之一。但是,计算语言学界构建的大量带有各种标注的语料库还不为语言学界所了解。这些语料库不仅可以开发语言智能系统的服务,也可以进行语言学的定性与定量分析研究。
因此,本文在梳理诸多语料库建设与应用情况的基础之上,从语料库的面向“群体”入手,将语料库划分为面向全文检索、语言计量和语言智能的语料库三个层次,重点介绍面向语言计量和语言智能的诸多语料库、相关期刊会议和平台,以及语料库的功用。从这三个层次出发来阐释语料库,希望有助于使用语料库的语言研究者确定研究范式,了解不同领域构建语料库的目的与用途,进而更好地使用语料库,优化完善建库的方案和技术。
1.语料库构建的三个层次
语料库建设过程是选取一定量的原始语言材料,将其清洗和电子化之后形成语言数据库,而后根据建库的目的,进行词、句、段落、篇章等不同层次的语言知识标注。对于大多数语料库而言,首要的构建目的是进行语言研究,通过在大规模语料库中检索特定字词的用例,丰富研究材料,以便观察和总结具体语言现象的用法和规律。而面对大型语料库中动辄成千上万的语言用例,逐一分析的定性方法,逐步被量化的计量分析法所取代。为了提高计量结果的可靠性,就需要在构建语料库时更加精细地设计语料的选取标准和标注深度。因此,以语言计量为主要研究方法的研究者,往往对于语料库有着更高的设计需求。
另一方面,伴随着人工智能技术的飞速发展,各种机器学习模型在计算语言学和自然语言处理领域不断取得突破,一方面提高了语言智能的技术水准,另一方面也带来了对高质量语料库的巨大需求。一般而言,机器学习模型无法单独运作,而需要三大要素互相配合,即算力、模型和数据。计算机的硬件算力是模型运算的支撑,而数据是模型运算的具体内容。对于语言的计算和处理来说,语言数据必不可少。语料库的规模越大,质量越高,标注信息越丰富,机器所能学习到的语言知识就越多。因此,面向语言智能的语料库建设,需要有清晰的问题定义和标注规范,以及严格的质量控制。大规模高质量的语料库为语言智能的发展起到了重要作用。
综上所述,从构建和使用语料库的目的出发,可以区分出三种语料库,即面向全文检索的全文语料库、面向语言计量研究的标注语料库和面向语言智能的高度结构化语料库(见图1)。

图1:语料库研究应用的三个层次
2.面向全文检索的全文语料库
20 世纪90 年代以来,互联网的发展催生了大量的网络电子文本,而纸质书籍的数字化为语料库、也为研究语言提供了海量数据。这些数据实现了电子文本化,有些经过了编辑校对等简单处理,有些标注作者、发表年份等元数据的简要信息。这种辅之以全文检索的电子数据,给语言研究者提供了丰富的字、词、句用例。
早期的全文语料库主要由欧美发达国家所构建,而这些包括英法德俄等在内的语言有着天然的词边界,便于进行基于词的全文检索。但也存在着较为复杂的形态变化,需要进行词形还原等操作,以实现词检索、共现搭配等应用。而对于没有明显词边界的汉语而言,则可以实现字检索和字频统计以及共现统计等简单功能。基于该层次语料库的研究大多是考证用例,检索较为典型的例句进行研究,以总结和佐证观点,如民俗学、社会学、人类学、文字学等研究,语言学领域中除考证典例之外,早期的词典编纂和语言教学研究也大多基于这一类语料库。周志锋(2011)选取《越谚》若干疑难方俗字词进行考释,肖贤彬(2006)查考《诗经》中若干带“有”“其”字疑难句子的释义,梁银峰(2023)发现我国大约从宋代开始发展出了完整体标记“了”的用法,刘成纪(2014)遍寻《尚书》《诗经》《论语》《左传》《国语》等春秋以前的文献,查考“以甘为美”及由此引发的味觉本源论的历史演变。近年来,国内学者自建了大量小型语料库,并开展了语言规则、语言情感、机构形象等多方面的研究(秦洪武等2022;钱玉彬2023;曾蕊蕊2023)。目前有大量全文库可供查考语言用例,部分全文库见表1。
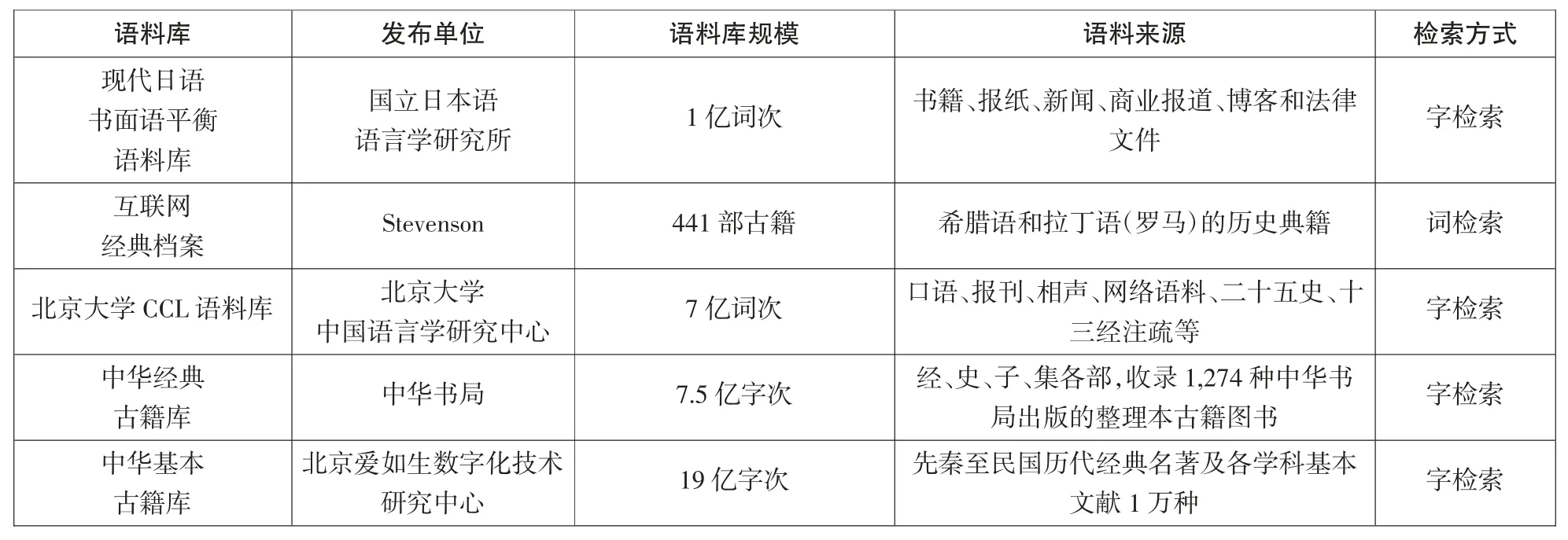
表1:全文语料库举例
尽管全文库可以实现简单的计量统计,但对于无分词标记的汉语而言,只能实现字的检索与频次统计,无法实现词的相关检索,更遑论义项计量、句法分析等基于深加工标注才能实现的研究内容。语言研究需求伴随计算机算力的发展而发展,使得语料库在语料领域选择、数据清洗、数据加工层次等方面都有了更高的要求,语言学逐渐用数据“说话”,使其成为研究结论的有力证据。
3.面向语言计量研究的标注语料库
早在计算机诞生以前,美国语言学家Zipf(1949)就基于词汇频率分布,提出了著名的齐夫定律(Zipf’s Law),而语言的计量研究更是随着电子语料库的建设而不断发展。功能学派代表人物Halliday(1991)明确提出了“语言系统天生就是概率性的”这一观点,说明使用必要的统计手段将这些概率信息提取出来,是语料库语言学的重要任务之一。语言计量逐渐进入学界研究视野,并引起极大关注,国内外越来越多地刊发或举办与计量研究相关的期刊或会议。
3.1 国内外代表性期刊
随着语料库的发展,语料库构建研究和基于语料库的语言学研究逐渐成为显学,学界也创建专刊以促进语料库语言学的发展。国外期刊主要有Corpus LinguisticsandLinguisticTheory(CLLT)、TheInternational Journal of Corpus Linguistics(IJCL)、Corpora、Applied CorpusLinguistics以及Journal of Quantitative Linguistics和Studies in Quantitative Linguistics,国内刊物较少,主要有《语料库语言学》和《语料库研究前沿》。
CLLT 关注音韵学、形态学、语义学、句法和语用学等研究领域,聚焦于理论研究。IJCL 收录语料库语言学各领域的方法论和应用研究,关注语言学(词汇、语法、形态学和社会语言学等)、应用语言学和翻译研究,如词汇和构式之间的相互作用、特殊搭配分析,也关注语料库语言学和计算语言学之间的衔接研究,如自动搭配抽取的评估,但整体侧重于理论研究。Corpora 既有理论研究,也积极探索以促进跨领域(应用语言学、计算语言学、语料库语言学、理论语言学)和跨学科(如文化研究、历史研究、文学研究)的思想和技术的交叉融合,如利用语料库研究仇恨言论等。Applied Corpus Linguistics 则关注语料库数据分析技术、理论化和个案研究,鼓励技术创新和数据可视化方法,包括语料库资源建设(如构建的精神分裂症语料库、印地语语料库),构建技术与工具(如多模态语料库分析工具),以及基于语料库的特定研究(如语料库技术融入教学方法)。Journal of Quantitative Linguistics关注如何用数学或统计的方法来研究语言现象,涵盖当代和历史语言学、社会语言学和方言学等,以及语音学、形态学、句法和语义学各个层次的研究。Studies in Quantitative Linguistics 不仅关注语言学的计量研究,也关注语言学中尚未仔细研究过的问题。其出版社专门针对“未解之谜”出版了相关丛书,为深化计量语言学的研究提供借鉴。
《语料库语言学》由北京外国语大学创立,常设语料库建设与理论探索、语言对比、翻译和中介语等栏目,更多关注于语料库与语言本体研究,较少关注面向计量的语言研究。新刊《语料库研究前沿》,主要关注语料库语言学研究、语料库翻译学研究、语料库文学文化研究、语料库本体研究,以及语言技术与数据研究等。
3.2 词法标注语料库
语料库的词汇层处理,一般称为词法分析,主要包括形态分析(分词)和词性标注,是语料库加工建设的基础工作之一。由于英语文本的词与词之间使用空格表示词边界,因此不需要作分词处理,但需要进行词形还原等形态分析。汉语文本没有词边界标记,需要先分词,才能进行后续标注与研究。词性标注则是给每个词标注词性(名词、动词、数词、助词等)。常见的词法标注语料库见表2。使用者可以基于这些语料库检索到“词”并统计词频、查找共现词搭配,统计并分析词法信息,应用到词典编纂、语义研究和语言教学等领域。苏新春(2017)编制的《义务教育常用词表(草案)》从频率、语境分布、语义分布、相对词频、位序等角度搭配词频实现分级研究。语义韵的研究也需要基于这种词法标注的语料库开展,李华勇(2019)基于语料库研究翻译汉语的语义韵,以cause 的汉译对应词“导致”“引起”为切入口,发现由于英汉翻译英语源语渗透效应、搭配词选择偏差和译者的积极调和等原因,翻译汉语语料库与原创汉语语料库的语义韵之间有显著区别。

表2:词法标注的语料库介绍
3.3 标注句法信息的语料库研究
3.3.1 句法标注语料库
经分词与词性标注处理后的语料库只能统计检索词语的频次,体现的是语言局部特点。而句法标注语料库的出现,使语言研究的层次从字词迈向句子。因此,句法标注是语料库语言学研究的前沿课题,以句法分析为基础的句法标注不仅可以把语料库的加工层次提升到新高度,也进一步提高了服务于语言研究的水准。
树库最初是为了自动句法分析而构建的,主要包括短语结构树库和依存树库。短语结构树库在生成句法理论的基础上进行了一些简化,标注句子的句法结构。最具代表性的树库为宾夕法尼亚大学构建的450 万词次的Penn Treebank 英语树库(Marcus et al.1993)和清华树库(周强2004)。依存树库旨在剖析句子各个单位之间的依存关系,最具代表性的树库为布拉格依存树库(Böhmová et al.2003)。
语言学家也构建了一批标注了特殊句法信息的语料库,如句型语料库、句式语料库和构式语料库等。赵淑华等(1995,1997)基于34 万现代汉语教材课文和小学课文进行句法分类统计和句法结构分析,分别建成两个句型语料库,即“小学语文课本句型语料库”和“现代汉语精读教材语料库”,统计了句型、短语比例,并考察了状语、补语语义指向的分布。郑定欧(2009)在2,000 万字次的语料库中选取了1 万个“把”字句,以对“把”字句的确指性、非光杆儿性以及处置性和及物性等三个特性做实证的检验。詹卫东(2021)构建了规模为1,000 多条的构式库,从句法、语义、语用三个层面描述构式的特征,以及构式间的关系(包括近义、反义、上下位关系等)。
中介语语料库的建设也往往包含句法信息的标注,初衷是为了研究语言使用错误。北京语言大学的HSK 动态作文语料库和中山大学的留学生全程性中介字字库及中介语文本语料库,均在字、词、语法、句式甚至标点符号使用等层面标注偏误信息。
3.3.2 计量应用
短语结构树可以表示句子较全面的句法信息,各种句法单位、搭配共现以及短语的结构与功能均能在短语结构树中得到体现。陈锋和陈小荷(2008)基于清华树库对汉语短语的语法功能分布进行了定量分析,发现汉语短语的语法功能表现出一定的聚合性,但自动句法分析中以类标记来估计短语语法功能效果欠佳。
基于依存句法的树库除了能进行一般的词类定量分析之外,还可以进行依存关系、依存距离和依存句法网络的统计分析。刘海涛(2007)基于自建汉语依存树库得到两种不同语体的汉语真实文本句法网络,并利用复杂网络分析工具对所建网络进行了分析研究,发现具有相同直径的两种语体的句法网络在平均度、平均路径长度、幂律指数和聚集系数方面的差别较为明显。刘海涛(2008)利用五个汉语依存句法树库,对汉语的依存距离和依存方向等句法属性进行了计量分析。统计发现,汉语中40%—50%的依存关系不是在相邻的词之间形成的,证明了汉语是一种支配词置后略占优势的混合型语言。
基于句法标注的树库是量化语言研究的基石,这些树库的建立有力推动了语法理论特别是依存语法理论的研究,也推进了特殊语言现象的研究。另外,由于依存树库结构简单而信息丰富,在句法研究、二语习得和少数民族语言研究等领域中起重要作用,在复杂网络分析中也占有一席之地,促进了更深层次加工的标注方案和语料库构建与量化研究的兴起,为谓词论元的语义标注、篇章关系标注等复杂标注语料库的出现奠定了基础。
4.面向语言智能的高度结构化语料库
人工智能与自然语言处理技术的飞速发展,对所使用的语言数据提出了更高的要求。语料所蕴含的信息不再只是简单、独立的词性与句法标签,而是专为语言模型所设计的一体化标注信息,甚至发展到语义、篇章、跨篇章以及多模态等层次。而对语言模型参数进行求解的过程就是基于语料库的建模过程。在计算语言学的发展中,这一过程经历了提取概率化规则、单点分类器、序列分类器、结构化学习模型、向量化表示和神经网络等不同的机器学习方法。语料库所标注的语言知识不再是服务于语言本体研究(如通过计量的方法发现语言特点),而是为了让机器拥有语言知识的自动标注能力,从而对生语料库进行自动粗加工,节约人力以构建更大规模、更深层次的语料库,甚至在一定程度上可以模仿人类的语言智能。这就要求语料库在标注体系上要清晰、可操作,使机器有较好的建模效果。
4.1 面向语言智能的语料库的特点
(1)标注规范定义清晰、可操作。美国计算语言学家Pustejovsky&Stubbs(2012)认为,“标注(Annotation)”一词是指向文本添加元数据信息以增强计算机执行自然语言处理能力的过程,因此考虑到机器学习的能力,作为标注依据的标注体系要求更加简洁、可操作,且一致性要高,尽量搁置争议。
(2)机器可学习、可建模计算。机器学习算法使用的“数据”是人工规整和标注了特定语言知识的数据,通过数学建模的机器学习算法获取概率化、向量化的语言知识,自动解析相关特征。
(3)模型效果可复现、可评测。评测是指对系统算法的性能和能力进行测试、评估和度量的过程。评测可以帮助研究员了解模型的解析能力与泛化能力,进而改进和优化算法模型。
4.2 面向语言智能的语料库相关会议、期刊和语料发布平台
随着语言智能技术的发展,计算语言学界的诸多会议也包含了语料库构建、计算应用方面的议题。其中,ACL(Annual Meeting of the Association for Computational Linguistics)、COLING(International Conference on Computational Linguistics)和EMNLP(Conference on Empirical Methods in Natural Language Processing)被称为自然语言处理领域的三大顶级国际会议。自然语言处理相关的会议还有CoNLL(The SIGNLL Conference on Computational Natural Language Learning)、SemEval(Semantic Evaluation)、LREC(Language Resources and Evaluation Conference)等,国内主要有CCL(The China National Conference on Computational Linguistics)会议。ACL 关注语音、词汇、语法和语义甚至篇章的相关研究,也关注语言资源的构建、信息抽取、信息检索和机器翻译等下游任务。COLING 关注词法、句法、语义等研究领域,也关注信息抽取、情感分析、文本推理等应用领域。EMNLP 关注自然语言处理的机器翻译、信息检索、信息提取等技术应用。CoNLL 重点关注语音、词汇、语法等计算语言学的理论、认知和科学方法和语言智能技术评测。SemEval 的主题为语义分析,涉及基础领域的词义和语义研究、篇章语义、临床医学和社会舆论的语义分析,每年组织大量的语义分析技术评测。LREC 主要关注语言资源的构建与解析,以及语言资源的智能应用。CCL 在关注现有自然语言处理的诸多任务之外,还关注语言计算理论与资源建设的研究。
除相关学术会议之外,国外刊物Language Resources and Evaluation 与国内刊物《中文信息学报》同样关注语言资源与语言智能。另外,学界也出现了规模较为庞大的语言资源发布平台以甄选高质量语言资源,如LDC(Linguistic Data Consortium)平台和ELRA(European Language Resources Association)平台。LDC 平台由宾夕法尼亚大学主办,主要通过创建和共享数据、工具和标准等资源来支持与语言相关的教育、研究和技术开发。ELRA 平台由欧洲诸多研究机构联合开发,旨在向整个学界提供人类语言技术的语言资源,目前已发布了1,625 种语言资源。
4.3 面向词法分析的语料库
自然语言处理的词法分析包括分词、形态分析、词性标注和命名实体识别等词汇层次的分析。语言学界对词的界定与词类的划分历来有所争议,分词规范与词性标注规范也呈多样性。在这些规范指导之下涌现出大量优质语料库,被广泛用于各种评测比赛中。
用于分词训练的代表语料库,主要有百万字规模的北京大学《人民日报》分词语料库、微软亚洲研究院MSRA 语料库等。中文的分词在多届SIGHAN 分词评测的推动之下已颇有成效,F1值为0.98,精度接近人工分词。
用于词性自动标记的典型语料库有《人民日报》词性标注语料库、Twitter 语料库,宾州树库和宾州中文树库也带有词性标记,目前汉语的自动词性标注精度已达到0.97,与英语相当。由于中文分词和词性规范发展较为成熟,研究视角开始转向古汉语和少数民族语言。第一届古代汉语分词和词性标注国际评测在盲测集上,封闭测试分词和词性标注的F1 值分别达到0.96 和0.92(李斌等2023)。
命名实体识别(Named Entity Identification)旨在确定人名、地名、机构名等类型的实体类型,是NLP的重要环节,在信息检索、信息抽取以及自动问答等领域都具有直接应用。不同标注方案有不同的分类,相关语料库主要有Ontonotes、Resume 和WeiBo 等,详细信息见表3。

表3:常见命名实体语料库信息表
4.4 面向句法语义分析的语料库
句子级的语言分析可以分为句法分析和语义分析。最初用于自然语言处理领域的句法分析是形式语法,但由于依存语法具有形式简洁、易于标注、便于应用等优点,逐渐成为NLP 的研究主流。基于形式语法和依存语法,构建了大批树库,但这些语料库的构建初衷并不是为了统计语言现象,而是为了构建自动句法分析器并提高分析性能,以实现自动标注的目的。
宾州树库以乔姆斯基的形式语法为理论基础,旨在分析句子的句法结构,树库的节点可以表示短语结构的非终节点,也可以表示词性和词语本身的终节点。最具代表性的树库为宾夕法尼亚大学构建的450 万词次的PTB 英语树库,但为了机器学习需要,PTB 大大简化了形式语法。此后,基于该框架构建了162 万词次的汉语CTB 树库(Xue et al.2005)、5 万词次的韩语PKT 树库和29 万词次的阿拉伯语ATB 树库,这类树库大多面向NLP 领域,只标记词性和粗略的句法、语义信息。除此之外,还有一些面向语言研究的代表性树库。如Susanne 树库、兰卡斯特树库(LPC)、国际英语语料库(ICE)等,以及诸多语言的树库。这些树库大都标注了词性、短语结构和语法功能等信息,标注体系更加精细。国内的短语句法树库有7 万多词次的北京大学汉语树库(周强等1997)、100 万词次的清华树库(周强2004)、中研院汉语树库(Huang et al.2000),另外也有学者对我国少数民族语言在树库方面进行了探索,如藏语、维吾尔语树库等。
依存语法由Tesnière 提出,认为谓词是句子核心,不受任何词的支配,却可支配句中其他词,所有受支配成分都以某种依存关系从属于其支配者。该理论指导下建立的依存树库(Dependency TreeBank),清晰地标注了各个词语之间的依存句法关系。国外代表性语料库有:布拉格依存树库(Böhmová et al.2003)和基于该体系构建的其他依存树库,如捷克语-英语双语依存树库、阿拉伯依存树库;斯坦福依存树库和芬兰语依存树库;通用依存树库(Nivre et al.2017)和基于此建立的韩语依存树库等100 多种依存树库。国内依存树库有哈尔滨工业大学构建的CDT 依存树库(Liu et al.2006)、苏州大学构建的SUCDT 树库(郭丽娟等2018,2019),另外清华大学也将TCT 转换为依存树库(周强2004)。
树库的建立使更深层次的标注体系成为可能,目前常见的语义标注(甚至篇章标注)语料库大多以句法分析树库为基础构建,即在宾州树库、依存树库等基础之上标注谓词-论元信息、语义角色和语义关系等语义信息,构建语义角色标注树库和语义依存树库。另外,由于树库结构上的局限性,越来越多研究者开始转向图结构,涌现出超边替代图语法(Hyperedge Replacement Graph Grammar)、有向无环图(directed acyclic graphs)等图结构表示方法,解决树结构无法体现论元共享等问题,典型的语义标注语料库见表4。高度结构化语料库也可以实现计量统计,探索语言信息,如Li 等(2019)建立了基于图结构的抽象语义表示(AMR)语料库,统计了图结构、非投影结构所占比例,后续还标注并统计了虚词、构式、省略等语言现象。

表4:常见语义标注数据库
4.5 面向篇章分析的语料库
目前,篇章级的语料库大多也是建立在句法树库的标注信息之上。另外,由于篇章标注覆盖面广、标注信息复杂,为了简单高效地研究某一领域,篇章信息的局部标注成为主流,大量学者开始建立篇章分析子领域语料库,如共指语料库、零形式语料库等。篇章级语料库的构建及相关技术的创新可以应用到自动篇章结构语义分析、事件关系图构建、机器翻译、文本摘要和信息提取等领域。
较为典型的篇章关系语料库有基于宾州树库(PTB)构建的宾州篇章树库(PDTB)(Prasad,et al.2008)、基于修辞结构理论(RST)构建的修辞结构库(RSTDT)(Carlson et al.2003)和基于宾州树库体系构建的哈工大中文篇章关系语料库(HIT-CDTB)。PDTB 的标注方案仅局限于同一段落的相邻句子,将相邻句子之间的关系分为5 类,即显性关系(Explicit)、隐性关系(Implicit)、替代关系(AltLex)、实体关系(EntRel)、无关系(NoRel)。在标签设定和框架结构上,共设定了三层意义关系标签,分为4 个大类、16 个子类及23 个小类。PDTB 还标注了关系及其论元之间的属性关系。RSTDT 将篇章中的修辞结构关系分为单核(Mononuclear)和多核(Multinuclear)两种。单核指存在关系的两个EDU 之间存在主次之分,多核则指双方地位平等,权重相等。RSTDT 包括53 种单核和25 种多核,共78 种,依据修辞关系之间的相近程度分为18类,附加核状态信息后共得到41 种不同的关系。张牧宇等(2014)基于互联网新闻语料建立了HIT-CDTB篇章语料库,标注了篇章句间语义关系,即篇章句间关系(细分为3 类)、关系元素(细分为3 类)、语义关系体系(细分为6 类)。另外,布拉格依存树库也标注了部分篇章级标注信息,标注了句内和篇章共指。
除了这些标注篇章关系的语料库,还有一些专门标注共指的语料库,如MS-AMR(O’Gorman et al.2018),语料选自非正式书面语体,多是论坛和博客,标注隐式角色、桥接关系(部分整体、组织成员)和共指信息。Ontonotes(Weischedel et al.2011)语料库标注句法信息、谓词-论元信息、共指信息以及命名实体识别。UMR(Uniform Meaning Representation)(Van Gysel et al.2021)标注了实体和事件的共指关系、子集关系。另外还有基于依存的共指标注语料库(Nedoluzhko et al.2009)、法汉指称链条平行语料库(胡霄钦,王秀丽2021)和汉语零指代语料库(孔芳等2021)等。
语料库的规模大小、质量优劣以及标注信息的多寡决定了语言智能模型的上限所在,在语言研究和语言建模中有重要意义。高度结构化语料库可以将过去主观总结的语言规则形式化表示,其标注规模一般超过十万词次。由于近乎是地毯式标注,在标注与构建过程中极易发现语言问题,以验证现有语言理论的有效性与局限性,不断推陈出新。但同时,高度结构化语料库也面临诸多问题:其一,机器可读、可运算的前提一般是需要分类标注的信息,而分类就难免存在“削足适履”的情况;其二,高度结构化语料库的构建目的在于实现相关任务的自动标注与分析,较少关注和分析语料库中的语言现象,应用于定量和定性分析的研究还很少。但是,基于这些深标注的语料库研发的语言智能系统,往往可以取得非常好的自动分析效果,十分值得语言学家进行具体分析和解释,也更值得在这些数据上进行量化研究,以推进对语言现象的规律性认识。
5.结语
语料库为人类观察、分析语言提供了基础数据资源。而海量的语料库又催促着语言计量研究的发展、语言智能计算模型的升级与优化。本文从语料库构建的目的和应用出发,将语料库分为面向全文检索、语言计量和语言智能三个层次。在“数据爆炸”的时代,语言研究已不再止步于典例查证,基于数学和统计学的计量研究思路逐渐受到重视,成为语料库语言学的主要研究阵地,学界也开始借助大规模语料库从全局视角研究语言共时和历时的发展与变化。同时,人工智能的高速发展也对语言数据质量、数据规模以及数据信息的结构化提出了更高的要求,如何建立人类语言的统一数学模型,实现真正的“语言智能”,仍需要语言学的不断创新。目前,语言研究呈百花待放的繁荣之态,仍有太多“未解之谜”正等待语料库语言研究的介入与探索,如何突破现有的计量指标与计量方法、如何提高数学模型的建模效果、如何利用高度结构化语料库研究语言规律乃至如何实现多模态的相互融合与转化,都是值得探索的方向。
注释:
①F1 值是精确率和召回率的调和平均数,可以用来评估模型效果。
猜你喜欢
中华诗词(2021年3期)2021-12-31
大连民族大学学报(2021年2期)2021-07-16
天津外国语大学学报(2020年1期)2020-03-25
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
海外华文教育(2016年1期)2017-01-20
语言与翻译(2015年4期)2015-07-18
中国科技术语(2012年3期)2012-03-20
当代外语研究(2010年3期)2010-03-20
当代修辞学(2010年1期)2010-01-23
