
基于因子分析的老年人幸福感评估方法研究
2024-04-06 15:27赵玉航
黑龙江科学 2024年5期
赵玉航
[中国石油大学(华东)理学院,山东 青岛 266555]
0 引言
随着我国经济的稳步增长,人们生活水平不断提高,“幸福”一词渐渐出现在大众视野。幸福是人们对生活满意程度的一种主观感受,这种主观的幸福感是衡量人们生活质量的综合性心理指标。幸福指数则在数字上反映了人们的生活状况与发展需求,是衡量主观幸福感具体程度的主观指标数值,是用于评估老年人是否健康的核心标准之一[1]。我国65岁以上老年人口数目不断增加,给我国社会与劳动力市场带来新的挑战。老年人的幸福水平直接反映了一个国家的经济水平与社会福祉,如何提升老年人的幸福感已成为研究热点。
自20世纪70年代以来,世界人口老龄化速度逐渐加快,我国成功实施计划生育,卫生保健事业不断进步,并将积极应对人口老龄化纳入国家战略,生育率、病死率不断下降且人均寿命不断增加。第四次中国城乡老年人生活状况抽样调查结果显示,60.8%的老年人“感到幸福”,比2000年的48.8%提升了12%。从城乡差值来看,城镇老年人口“感到幸福”的比例为68.1%,比2000年的66.2%提升了1.9%,农村老年人口“感到幸福”的比例为53.1%[2]。但由于高龄及无劳动能力、无经济来源等问题的存在,老年人的健康状况与生活质量依然需要引起关注,如何提升老年人的幸福指数与评估老年人是否幸福仍是公共卫生研究领域的热点话题。
从现有文献来看,测量老年人幸福感的研究工具有十余种,大多是引自国外的量表,或直接使用,或经修订后使用,调研方式以结构化问卷为主。测量工具对老年人幸福感的全面了解与把握越来越准确,能够通过人格、社会及其他情景间的交互关系测量与评估幸福感。目前,学界较知名且认可度较高的幸福感测量方法是经验取样法,但其实施成本高,测量误差较大[3]。Kahneman 等提出昔日再现法,将日记重现改为生活事件回顾表,提高了调查表的信度与效度,并能在一定程度上减轻了被试人员的负担,在方法上更加科学有效[4、5]。刘国珍等在总结梳理幸福含义的基础上,区分形成幸福的四种测量范式,包括生活质量幸福测量、情绪状态幸福测量、自我完善幸福测量与日常体验幸福测量,说明了各种测量范式下主要的测量工具与方法[6]。朱雅丽等从经济保障、健康状况、生活照料与精神慰藉四个维度构建幸福感评价指标体系[7]。
大多数研究从定性的角度进行分析,并没有数据佐证,也没有从定量的角度利用统计学方法对老年人幸福感进行研究。采用因子分析法,可以从变量群中提取共性因子,在众多变量中找出隐藏的具有代表性的因子,将相同本质的变量归入一个因子,减少变量的数目,检验变量间关系的假设。以2018—2019年老年健康影响因素调查数据为依据,利用因子分析法对老年人幸福指数进行定量分析,通过累计方差贡献率对提取的因子进行加权得到综合得分,构建老年人幸福指数,以期实现对“幸福”这一模糊名词的定量处理。
1 数据来源及处理
数据来自中国老年健康影响因素跟踪调查社区数据集,其由北京大学“中国老年健康影响因素跟踪调查”课题组在1998—2014年跟踪调查的基础上,通过查询国内公开发行的各类统计年鉴及数据库,搜集整理中国老年健康影响因素跟踪调查样本所覆盖的全国23个省市自治区860多个县、县级市或区的社会经济、医疗与老龄服务、空气污染与其他环境污染等社区信息得到的,是与个体微观跟踪调查数据有机整合的社区中观数据,能够为政策研究提供可靠的数据支持。
选取2018—2019年老年健康影响因素调查数据,共计15874个样本量,17个特征变量信息,具体的特征变量信息如表1所示。

表1 变量信息Tab.1 Variable information
采用调查问卷的方式进行数据收集,极易出现调查对象漏填的情况,故特征变量不可避免会出现数据缺失。变量e62 (子女照顾情况) 的缺失比例为70.85%,表明该变量大部分数据是缺失的,不能进行后续的统计分析与建模,故剔除该变量。其余变量中,e67(子女一周照顾时间) 的缺失比例为24.13%,占比最大。有9个特征变量缺失值占比在10%以下,b11(自认生活状况)的缺失比例最小,为0.86%。详见图1。

图1 特征变量数据缺失占比Fig.1 Proportion of missing feature variable data
采用KNN算法填补缺失值。KNN算法又称为近邻分类算法(k-nearest neighbor classification),是一种广泛使用的缺失值插补方法,其本质是通过距离测量识别相邻点,通常相邻点具有近似的数据特征。在机器学习中,通过在训练集中找到与该实例最邻近的k个样本点,利用k个相似样本点间的数据特征估计缺失的特征数据。在KNN算法中,两样本点间距离度量一般采用欧式距离,公式如下:
(1)
将欧式距离相近的归为一类,最后划分为K个类。对于数值型数据,取同一类的平均数填补缺失值。对于分类型数据,取同一类的众数填充缺失值。通过python中的KNNImputer模块对数据集进行缺失值填充,最终共处理缺失值30 001个。
2 算法实现
2.1 操作步骤
1)确定待分析的原有若干变量是否适合进行因子分析。一般的正交因子模型为:
(2)
转换为矩阵形式为:
(3)
因子分析是从众多的原始变量中重构少数几个具有代表意义的因子变量的过程,其潜在的要求为原有变量间要具有较强的相关性。故需先进行相关性分析,计算原始变量间的相关系数矩阵。在进行原始变量的相关分析之前,需对输入的原始数据进行标准化计算。
相关系数的值介于-1与1之间,即-1≤r≤1,其性质如下:
当r>0时,表示两变量正相关,r<0时,两变量为负相关。
当|r|=1时,表示两变量为完全线性相关,即为函数关系。
当r=0时,表示两变量间无线性相关关系。
当0<|r|<1时,表示两变量存在一定程度的线性相关。且|r|越接近1,两变量间线性关系越密切,|r|越接近于0,表示两变量的线性相关关系越弱。
一般可按三级划分:|r|<0.4为低度线性相关,0.4≤|r|<0.7为显著性相关,0.7≤|r|<1为高度线性相关。
2)构造因子变量。因子分析中有很多确定因子变量的方法,如基于主成分模型的主成分分析与基于因子分析模型的主轴因子法、极大似然法、最小二乘法等,前者应用最为广泛。
主成分分析法通过坐标变换将原始变量作线性变化,转换为另一组不相关的变量(主成分)。求相关系数矩阵的特征根λi(λ1>λ2>…>λp>0)与相应的标准正交的特征向量li,根据相关系数矩阵的特征根,即公共因子Fi的方差贡献(等于因子载荷矩阵A中第j列各元素的平方和),计算公共因子Fi的方差贡献率CV与累积贡献率CVC。公式如下:
(4)
(5)
根据因子的累积方差贡献率来确定公因子个数,一般取累积贡献率大于85%的特征值所对应的第一、第二、…、第m(m≤p)个主成分。
3) 因子变量的命名解释。因子变量的命名解释是因子分析的另一个核心问题,在实际应用分析中,主要通过对因子载荷矩阵进行分析得到因子变量与原有变量间的关系,从而对新的因子变量进行命名。有时因子载荷矩阵的解释性不好,需进行因子旋转,使原有因子变量更具有可解释性。因子旋转的主要方法有正交旋转与斜交旋转,方差最大正交旋转最为常用,基本思想是使公共因子的相对负荷的方差之和最大,且保持原公共因子的正交性与公共方差总和不变。可使每个因子上具有最大载荷的变量数最小,故可简化对因子的解释。
4) 计算因子变量得分。因子变量确定后,为确定因子得分,即样本数据在不同因子上的具体数据值,采用回归法、Bartlette法等进行计算。计算因子得分应首先将因子变量表示为原始变量的线性组合。即:
(6)
2.2 评定标准
1)KMO检验。KMO检验是抽样适合性检验,对原始变量间的简相关系数与偏相关系数的相对大小进行检验。计算公式为:
(7)
若原始数据中确实存在公共因子,则各变量间的偏相关系数应该很小,这时,KMO的值接近于1,原数据适用于因子分析。在实际分析中,KMO统计量大于0.7可视为效果比较好。
2)Bartlett’s球状检验。Bartlett’s球状检验用于检验相关阵中各变量间的相关性,是否为单位阵,即检验各个变量是否各自独立。Bartlett’s球形检验判断中,若相关阵是单位阵,则各变量独立因子分析法无效。当P值小于0.05时说明符合标准,数据呈球形分布,各变量在一定程度上相互独立。

(8)
其中,
(9)
3 研究结果
由于所选数据指标受量纲大小的影响,首先要对数据进行标准化处理,基于python进行因子分析建模。
3.1 热力图
热力图能够体现各变量间的相关关系。f651a2.1与f651a2 变量的相关系数为1,f651a1.1与f651a1变量的相关系数为1,b12与b11存在高度相关关系。相关系数矩阵为奇异矩阵,无法求出特征值与特征向量。考虑剔除f651a1.1、f651a2.1与b11强相关变量构造相关系数矩阵,见图2。

图2 修改变量后的相关系数矩阵Fig.2 Correlation coefficient matrix after modifying variables
3.2 相关系数测算
本研究中KMO值为0.8434233,说明适合做因子分析。且Bartlett’s检验P值小于0.05,即变量间存在显著的相关性。详见表2。
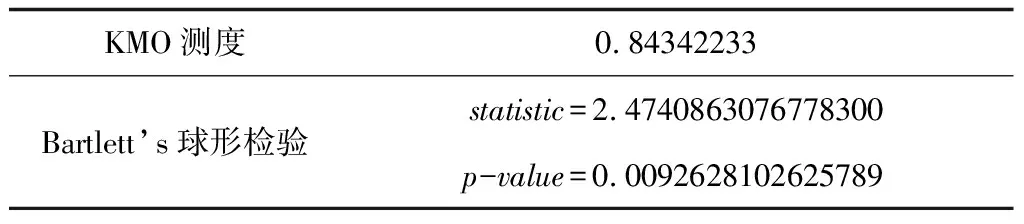
表2 KMO与Bartlett’s的检验结果Tab.2 KMO and Bartlett’s test results
3.3 因子分析
前四个公共因子方差贡献率为0.8903,大于0.85,说明其可以解释大部分变量,故选取四个公共因子作为影响因素,详见表3。
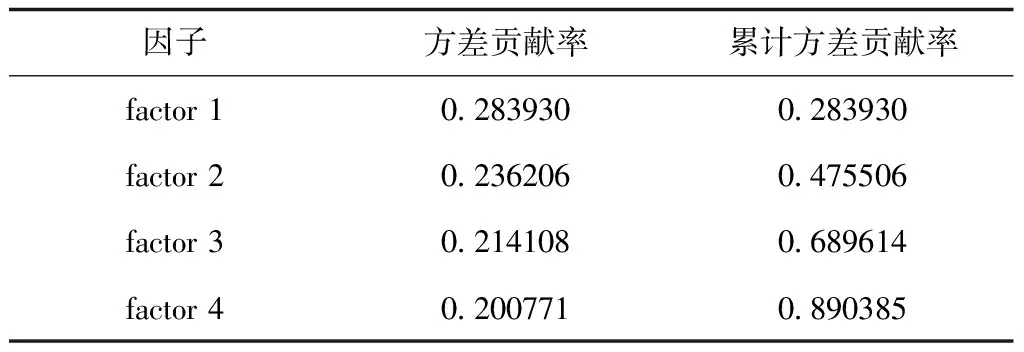
表3 方差贡献率Tab.3 Variance contribution rate
子女经济来源变量与医疗费用变量在factor 1上载荷较大,这些变量与经济相关,故命名为经济因子指数。是否精力充沛、自认健康状况与睡眠时间在factor 2上载荷较大,这些变量与个人的身体健康相关,故命名为健康因子。同居人数、住房类型、子女照顾情况等变量在factor 3上载荷较大,这些变量与老年人的生活息息相关,故命名为生活因子。社区服务种类与是否参加社会活动在factor 4上载荷数较大,这些变量与社会服务相关,故命名为社会因子[12]。详见表4、表5。
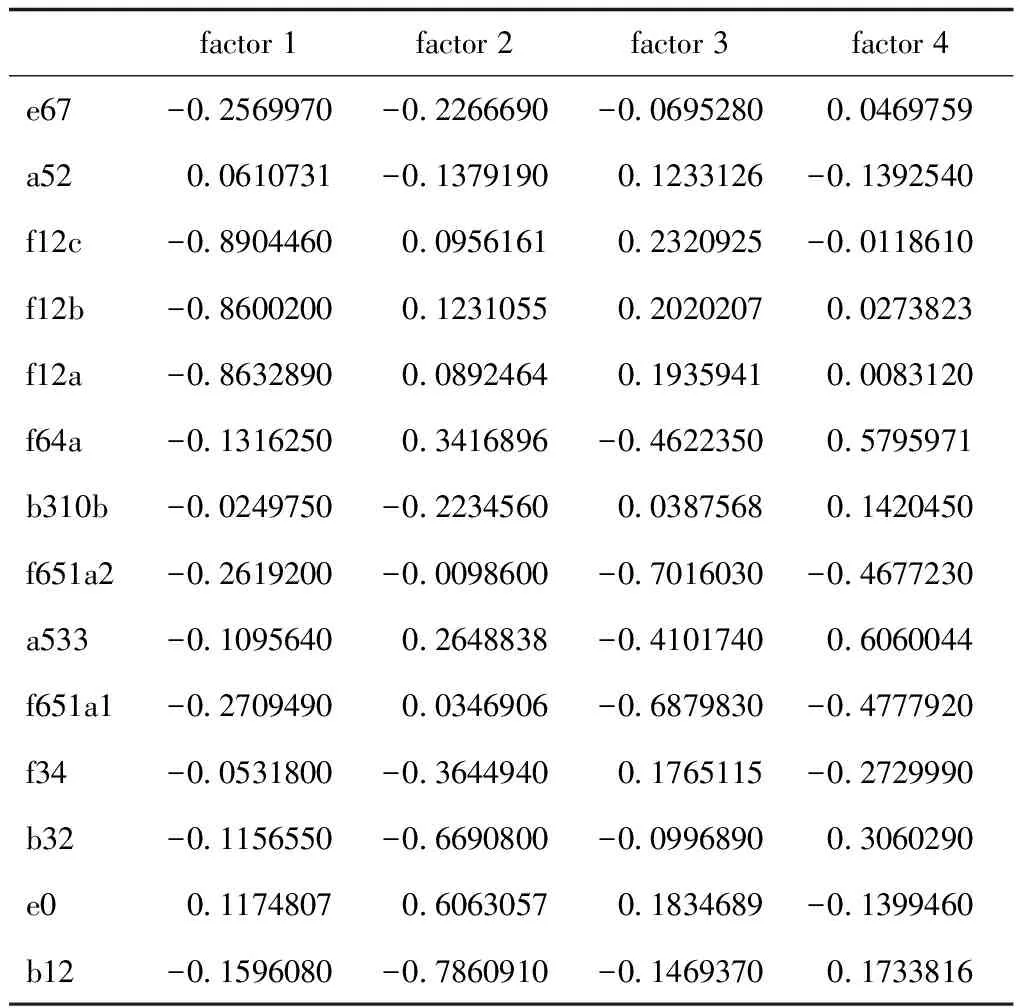
表4 因子旋转矩阵Tab.4 Factor rotation matrix

表5 因子命名与特征变量Tab.5 Factor naming and feature variables
3.4 老年人幸福指数的搭建
四个公共因子的方差贡献率分别为:0.283930、0.236206、0.214108与0.200771,对样本的因子得分进行加权平均,得到老年人幸福指数的测量模型:
老年人幸福指数=0.283930×样本经济因子+0.236206×样本健康因子+0.214108×样本生活因子+0.200771×样本生活因子
对最后的综合指数进行指数化处理,将得分取值压缩到[0,100],得到的部分老年人幸福指数,详见表6。

表6 部分老年人幸福指数Tab.6 Part of the elderly happiness index
4 结论
基于北京大学“中国老年健康影响因素跟踪调查”课题组2018—2019年的问卷调查数据,使用KNN填充法进行数据填补,无法完全反映各老年人的真实情况。且因子分析是一种常用的降维方法,选取4个公共因子不可避免会导致一些信息的损失。后续研究可考虑使用主成分分析与LDA相关方法。
猜你喜欢
中学生数理化·七年级数学人教版(2023年6期)2023-05-25
好日子(2022年3期)2022-06-01
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
英语文摘(2020年11期)2020-02-06
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
中国生殖健康(2019年7期)2019-01-06
初中生世界·九年级(2017年10期)2017-11-08
数学年刊A辑(中文版)(2015年2期)2015-10-30
