
肝细胞癌自动化BCLC分期模型研究
2024-04-15 08:00张冰许庆祎
中国卫生标准管理 2024年5期
张冰 许庆祎
肝细胞癌是我国最常见的恶性肿瘤之一,其发病率在所有恶性肿瘤中排第4位,病死率排第3位,严重威胁我国人民的生命健康[1]。巴塞罗那分期(Barcelona clinic liver cancer,BCLC)是目前国际广泛认可的HCC重要分期之一,用于判断患者肿瘤情况,是制订临床诊疗方案以及评估患者预后的重要根据[2]。BCLC分期自1999年初次提出后[3],至今历经多次版本更新,故除经系统培训的肝脏专科医师外,大部分全科医师及非肝脏专科医师对BCLC分期均存在不同程度的认识不足。尤其基层医院,因知识更新渠道缺乏、对专科疾病诊疗经验不足等原因,可能在HCC患者的病情判断、指导分诊等方面出现误差,从而影响患者及时获得有效治疗。而学术研究中,在需对大量既往病例进行即时、准确分期时,也存在耗时较长、人为的主观错误难以避免等问题。目前,大数据时代激发的新技术进步和多学科交叉融合,使实现HCC的自动化BCLC分期成为可能。因此本研究拟依托自主研发建立的HCC大数据平台,构建自动化BCLC分期模型,以服务于临床诊疗及学术研究工作。
1 资料与方法
1.1 一般资料
收集福建医科大学孟超肝胆医院2020年1月—2022年12月收治的HCC患者的临床资料,通过数据仓库技术(extract-transform-load,ETL)工具[4]构建患者的全维度数据集(每个病例含700个维度)。选取2020年1月—2022年12月收治的1 076例HCC患者,用于构建HCC自动化BCLC分期模型,其中926例作为训练集,150例作为验证集。随机抽取2020年1月—2022年12月收治的HCC患者共191例,进行既往病例测试;选择2020年1月—2022年12月收治的180例HCC患者,进行新增病例测试。纳入标准:(1)入院后完善影像学、乙肝两对半、甲胎蛋白(alpha-fetoprotein,AFP)等检查,临床诊断为HCC。(2)行手术或穿刺活检者病理确诊为HCC。(3)临床资料准确完整。排除标准:(1)手术或穿刺病理诊断其他类型肝癌或转移瘤等。(2)临床资料不完整。 本次试验经医院医学伦理会批准(20190512)。
1.2 方法
采用基于机器学习的自然语言处理和基于Python语言的XGBoost模块等方法构建自动化BCLC分期模型。
1.2.1 数据采集
通过数据库自动采集器实时采集电子病历系统(electronic medical record,EMR)/医院信息系统(hospital information system,HIS)/影像归档和通信系统(picture archiving and communication system,PACS)等系统的信息,将1 076例HCC患者的全维度数据集(每个病例含700个维度)存放在接口库。
1.2.2 数据清洗
系统设定跟踪系统,接口库有内容更新,自动提取患者住院号,收集诊断、检验、影像等数据,对数据进行清洗,实现数据的统计口径一致、剔除无用和冗余数据的工作后,将高维向量集写入中间库。
1.2.3 数据整合
将来自于中间库的数据按照科研所需要的资源按照人口库、检验库、诊断库、病史库等写入到基础库中。
1.2.4 数据存储
基础库存放在数据存储中,提供相关结果给各个应用调用。
1.2.5 数据分析
以2016年BCLC分期[5]为标准用于建模,从基础库中提取诊断、检验及影像数据,利用基于医学语言的自然语言处理,通过基于机器学习的自然语言处理[6]及决策树等方法对影像报告的描述和诊断结论进行医学文本的自然语言处理后,从中选取肝性脑病、腹水、总胆红素、白蛋白、凝血酶原时间、肿瘤个数、肿瘤直径、门静脉癌栓情况、肝外转移情况、患者体力情况等12个相关维度,写入BCLC分期标准库,见图1。
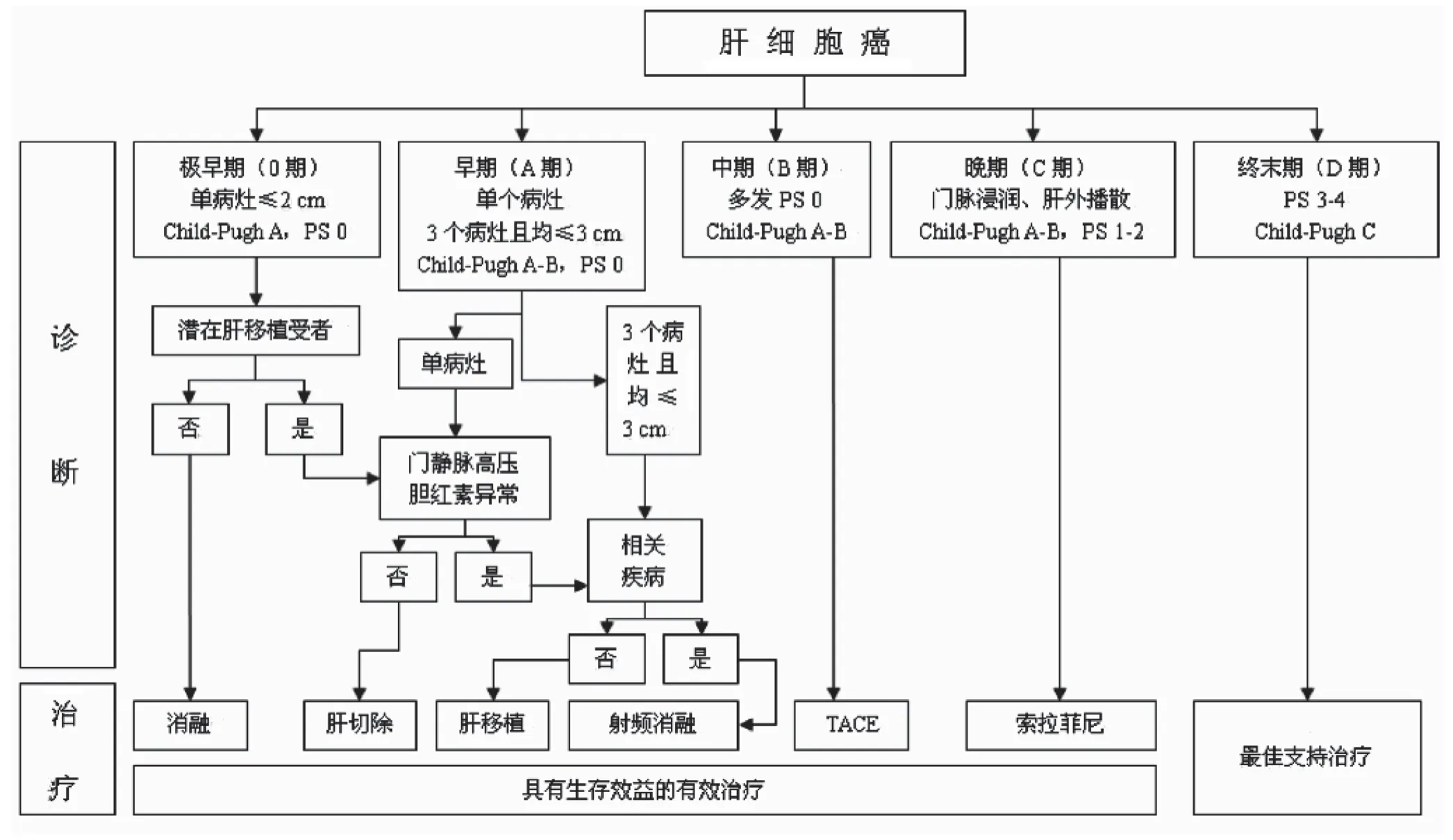
图1 2016年BCLC分期
1.2.6 建模原理
决策树是将空间用超平面进行划分的一种方法。决策树的boost方法:是一个迭代的过程,每一次新的训练都是为了改进上一次的结果。XGBOOST算法[7]是一种全新的迭代决策树算法,可以提供高精度的预测,该算法由多棵决策树组成,所有树的结论累加起来做最终结果。XGBOOTS的预测函数如公式1所示:
XGBOOTS的目标函数如公式2所示:
XGBOOTS的目标函数为:泰勒二阶展开和巧妙的定义了正则项,用求解到的数值作为树的预测值,见图2。

图2 XGBOOTS目标函数的泰勒展开
1.2.7 模型建立及验证
导入BCLC分期标准库,通过含926例HCC患者的训练集,采用基于机器学习的自然语言处理和基于Python语言的XGBoost模块等方法,构建HCC自动化BCLC分期模型,使用含150例HCC患者的验证集对模型进行验证,记录模型准确率。
1.3 HCC自动化BCLC分期模型测试
1.3.1 测试分组
模型测试分为既往病例测试和新增病例测试。由2名肝胆外科主治医师对测试病例根据2016年BCLC分期为标准进行双盲式人工分期,获得标准分期用于校正。在大数据平台里电子病历库中检索测试病例的原始病历中所记录的BCLC分期,定义为病例记录分期。利用自动化BCLC分期模型对测试病例进行分期,获得模型自动化分期,记录测试病例开始导入至分期结束的总耗时。
1.3.2 测试方法
本研究定义模型测试中HCC自动化BCLC分期模型准确率与病例记录分期的准确率误差不超过5%,即认为建模成功。用标准分期分别校正模型自动化分期及病例记录分期,记录二者准确率,找出错误案例,并逐份抽取原始病历分析错误原因。
1.4 统计学处理
采用SPSS 23.0统计学软件进行分析。计量资料以(±s)表示,组间比较采用独立样本均数t检验;计数资料用n(%)表示,行χ2检验。P< 0.05为差异有统计学意义。
2 结果
2.1 建模成功
用含150个病例的验证集对所构建的HCC自动化BCLC分期模型进行验证,准确率为93.33%,提示建模成功。
2.2 病例测试结果
既往病例测试结果提示,经标准分期校正,自动化分期准确率为98.43%,错误3例,其中0期1例,A期2例,B期0例,C期0例,D期0例,总耗时约19 s。错误原因主要是机器对于CT、MRI、腹部彩超报告中肿瘤个数及肿瘤直径的判断出现错误。记录分期准确率为96.33%,错误7例,其中0期2例,A期5例,B期0例,C期0例,D期0例。错误原因包括:(1)电子胃镜报告可见食管胃底静脉曲张,提示门静脉高压,只关注CT报告,未关注胃镜报告结果,混淆0期与A期。(2)生化全套提示总胆红素值异常,仅用于 Child-Pugh评分,未理解对分期影响,混淆0期及A期。(3) Child-Pugh评分为Child B期,只关注肿瘤个数及直径,混淆0期与A期。
2.3 新增病例测试结果
新增病例测试结果提示,经标准分期校正,自动化分期准确率为95.56%,错误8例,其中0期1例,A期1例,B期4例,C期2例,D期0例,总耗时约18 s。错误原因包括:(1)主要是机器对于CT、MRI、腹部彩超报告中肿瘤个数及肿瘤直径的判断出现错误。(2)彩超报告中提示肝外转移灶待排,CT、MRI报告同一部位无转移,机器逻辑为报告出现一处转移记录就是出现转移,导致分期错误。(3)将巨块型肿瘤周围1个子灶一并统计肿瘤个数,归入B期。记录分期准确率为96.11%,错误7例,其中0期2例,A期1例,B期2例,C期2例,D期0例。错误原因包括:(1)CT、MRI报告可见食管胃底静脉曲张,提示门静脉高压,未理解对分期影响,混淆0期与A期。(2)将肝静脉癌栓及胆管癌栓归入C期。(4)CT报告提示肝外转移(肾上腺),未看到。(5)将均<3 cm的3个肿瘤归入B期。
3 讨论
“大数据”时代的来临已在多个学科领域引发大变革,目前《Nature》《Science》等顶尖学术期刊均推出相应专刊探讨其应用,健康医疗大数据更受到全球范围内的关注、重视。随着大数据技术的进步、成熟,现已可将临床记录、医学影像、检验信息等不同形式的数据迅速而有效地挖掘并有机整合,并进行及时的计算和分析。
BCLC分期是临床上用于分析HCC的肿瘤情况、制订诊疗方案及评估预后的重要依据。自1999年LLOVET等[8]首次提出后,BCLC分期历经2005、2010、2016年多个版本更新。2005年分期去除了Okuda分期,将单个病灶直径在2 cm以下定义为0期(极早期),早期治疗方案加入射频消融(radiofrequency ablation,RFA),经导管动脉化疗栓塞术(transcatheter arterial chemoembolization,TACE)成为B期首选治疗,C期建议参加药物Ⅱ期研究或随机对照研究[9]。2016年提出0期患者是潜在肝移植受者概念,明确将直径2 cm也定义为0期,分期治疗方面取消所谓根治性及非根治性疗法的说法,进而提出0期、A期、B期、C期均应采取具有生存获益的有效治疗[10]。病例的具体BCLC分期结果常会出现改变,如对既往病例进行人工校正费时费力,且不可避免地会发生主观性错误。另外,非肝脏专科医生对专科知识的认识不足和相对滞后也可能导致其错判肿瘤分期。而这些情况都将对HCC的分级诊疗和临床研究带来不利影响。因此,实现HCC的自动化BCLC分期具有积极的临床实用价值。
本研究利用大数据方法学成功构建了HCC自动化BCLC分期模型,并分别用既往病例和新增病例进行测试,通过富有经验的专科医师的双盲分期来评判测试准确率。总测试病例共371例,模型自动化分期准确率为97.04%(错误11例),而病例记录分期准确率为96.23%(错误14例),两者大致相当。经逐例分析错判病例发现,病例记录分期错误主要集中在0期、A期。错误发生原因主要包括:(1)部分一线医生对BCLC分期的认识不充分。(2)既往病例依据旧标准分期并记录。(3)注意力不够集中等原因导致主观错误发生。这些都说明人工分期存在着主观错误不可避免、学习成本高等问题。模型自动化分期错误则主要是由于肿瘤直径、肿瘤个数、门静脉癌栓、肝外转移灶等相关数据主要从影像学资料提取,而受限于影像科报告医师的临床经验差异、个人习惯不同等因素,该类别存在大量的非结构化数据;虽已经过标准化处理,仍存在部分病例出现维度识别错误的问题,最终导致自动化分期错误。另外,既往病例测试的自动化分期准确率(98.43%)高于新增病例测试(95.56%),经分析错误病例后,考虑由于本团队过去建设生物信息样本库时已对既往病历资料完成了数据的人工采集归类,相关维度信息更加详细、模块化,故识别提取维度的难度较低、准确度更高。而新增病例是用自动采集器直接从原始病历、报告等第一手资料中提取维度,难度相对较高而导致个别维度信息提取错误。在模型测试过程中所发现的上述缺陷可基于机器学习,进行程序优化以进一步提高准确率[11]。
模型自动化分期的准确率略高于病例记录分期,且有其独有优势:(1)不断迭代的BCLC分期学习成本高,年轻医师在大量人工分期时无法避免出现错误,而模型分期不存在因主观导致的错误,可辅助临床医师做出更精准判断及减少错误,降低学习成本。(2)大数据时代,进行HCC相关学术研究,需要挖掘海量的历史数据,BCLC分期版本更迭后,需要对海量的既往病例进行重新分期,人工识别工作量大、耗时长,模型分期则可在短时间内完成分期更新,并可根据以后版本进行实时更新,降低时间成本。(3)BCLC分期作为常用HCC分期,在基层医院因学习渠道窄、接触相关病例少等问题,普及困难大,容易导致患者治疗的延误,自动化BCLC分期模型建立后可依托互联网进行推广,有助于建立医联体中更规范的HCC分级诊疗体制。(4)在机器学习下可逐渐优化模型自身,准确率不断提高。
在建模过程中,发现诸多不足,模型仍有改进的空间。医学影像库的纳入仅限于报告的提取,图像的提取分析功能仍处于研究阶段,HCC的诊断强烈依赖于影像,基层医院经验不足,导致部分影像学诊断可信度不高,影响了模型的使用推广,对此可基于医联体,建立上下级医院之间沟通学习的渠道。医学检验库的纳入发现不同时期的检验结果因检验试剂、方法、设备而出现不一致的问题,检验数据的标准化或一致性需要进一步研究。电子病历库的纳入发现因个人习惯、经验及大量非结构化部分对数据的提取处理分析提出了挑战,需根据病例书写规范进一步进行规范化、模块化管理。最后是大数据平台的管理面临全新的挑战,包括安全方面、隐私方面、分享交换方面在内,都需要进一步探索[12]。
综上所述,HCC自动化BCLC分期模型高效、精准,在数据标准化方面尚有改进空间,值得向临床推广。
猜你喜欢
小天使·一年级语数英综合(2022年2期)2022-03-30
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
作文评点报·低幼版(2020年25期)2020-07-23
中国交通信息化(2018年5期)2018-08-21
湖南畜牧兽医(2016年1期)2016-06-05
人生十六七(2015年29期)2015-02-28
右江医学(2014年1期)2014-03-22
右江医学(2014年1期)2014-03-22
